

NoSQL – коротко о главном
Что такое NoSQL
Когда мы разбирали виды баз данных, то сказали, что они бывают реляционные и все остальные. Реляционные — самые распространённые, вы встретите их под капотом большинства сайтов, чаще всего они управляются через систему MySQL.
Но одно решение не может подходить всем и всегда. Сегодня поговорим обо всех остальных вариантах, которые собраны под единым большим термином NoSQL — это общее название для нереляционных баз данных.
Способ организации данных
В SQL-базах всё просто: есть, условно говоря, таблицы, и есть связи между ними. Все данные хранятся в этих таблицах.
В NoSQL-базах всё иначе — там может не быть таблиц, а вместо них — свои модели данных. Каждая из них подходит под свои задачи, универсальной нет. Вот основные модели:
Ключ-значение
У каждой записи есть название поля и его значение. Например:
name: ‘Миша’
today: ‘9/09/2020’
president: ‘Путин’
writer: ‘Пушкин’
pogoda: ‘ну такая’
Первая часть — это ключ, вторая часть — значение. И можно подсыпать сколько хочешь новых ключей.
Это полезно, например, для словарей или механизмов автозамены: «Если встретилось такое слово — замени на вот такое».
Колонки
Представьте себе одну огромную таблицу, в которой хранятся все данные в базе. Отличие от традиционной схемы в том, что в SQL-базах работа идёт со строками, а здесь — с колонками. Например, если в такую базу занести список из 250 лучших фильмов с названиями, актёрами и режиссёрами, то все названия можно получить с помощью только одного запроса и одного обращения к базе. В случае с SQL таких обращений к базе было бы 250 — по одному на каждую строку.
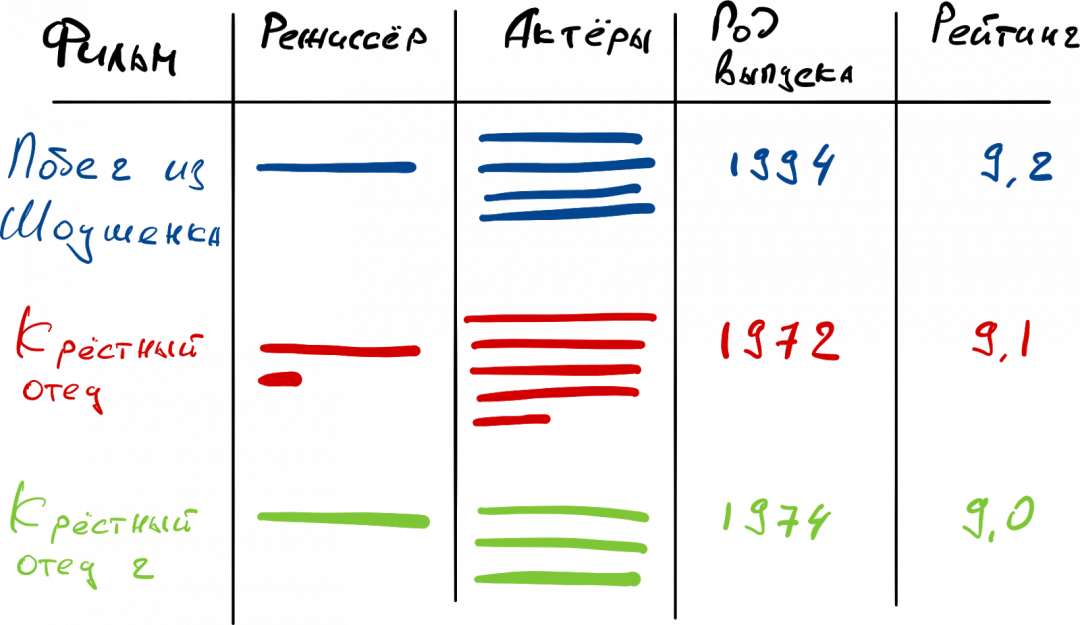
Графы
Если ваши данные можно представить в виде графа или дерева, то вам подойдёт и база данных с таким же подходом к хранению и поиску.
Дерево — это когда данные хранятся по системе «родитель — отпрыски». Есть некий родительский кусок данных, у него есть связанные с ним отпрыски. У тех тоже могут быть свои отпрыски и так далее. Каждая единица данных может быть чьим-то отпрыском (но только кого-то одного) и иметь сколько-то собственных отпрысков.
В деревьях удобно хранить данные, например, для поисковых алгоритмов. В «деревьях» также хранятся файлы на вашем компьютере: есть корневой каталог, в нём вложенные папки, в них ещё папки, в них файлы. Один и тот же файл не может храниться одновременно в двух местах.
Графы — это когда данные связаны вообще как хочешь. Один кусок данных может быть связан с любыми другими в любом количестве и в любом направлении. Дерево — частный случай графа.
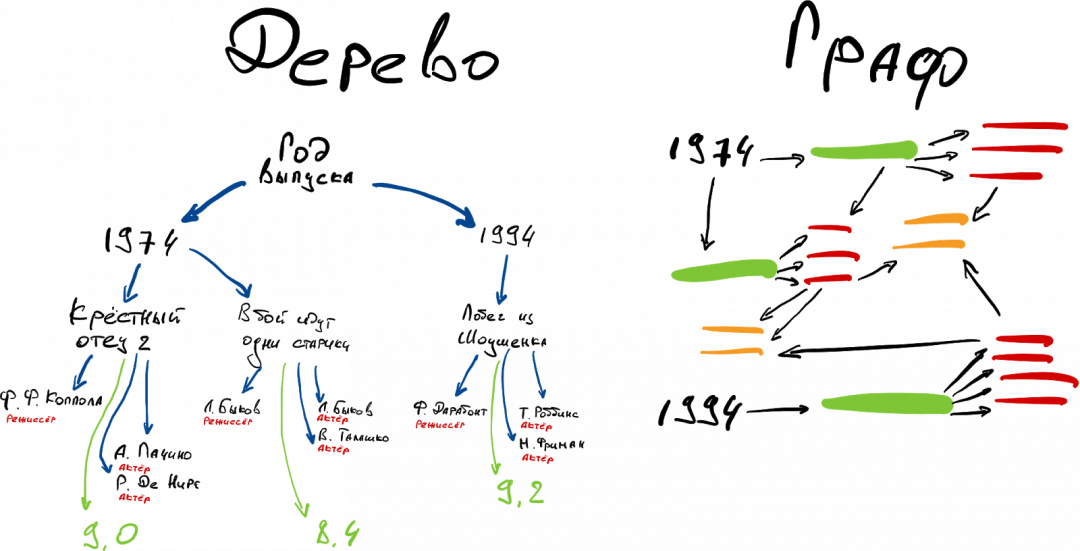
Документы
Вот это космос, смотрите.
Если мы храним данные в таблице, у нас есть столбцы и строки. И если у нас про кого-то есть данные, а про другого нет, — где-то в таблице будут пропуски. А если в таблице нет нужного столбца, а нам нужно положить в неё новый тип данных, нам придётся создавать новый столбец, и он для всех будет пустым:
Обзор NOSQL баз данных
 В последние годы наблюдается стремительный взлет популярности семейства технологий хранения данных, известных как NOSQL (дерзкий акроним от Not Only SQL (Не только SQL), или акроним от еще более категоричного No to SQL (Нет SQL)). Но сам по себе термин NOSQL означает лишь, что такие хранилища данных не являются SQL-ориентированными реляционными базами данных, а интересным и полезным набором разнообразных технологий хранения, имеющих множество эксплуатационных, функциональных и архитектурных характеристик.
В последние годы наблюдается стремительный взлет популярности семейства технологий хранения данных, известных как NOSQL (дерзкий акроним от Not Only SQL (Не только SQL), или акроним от еще более категоричного No to SQL (Нет SQL)). Но сам по себе термин NOSQL означает лишь, что такие хранилища данных не являются SQL-ориентированными реляционными базами данных, а интересным и полезным набором разнообразных технологий хранения, имеющих множество эксплуатационных, функциональных и архитектурных характеристик.
Что послужило причиной создания этих новых баз данных? Какие задачи они призваны решить? Здесь будут рассмотрены некоторые из проблем обработки данных, которые возникли в течение последнего десятилетия. Далее будут описаны четыре семейства NOSQL-баз данных, в том числе графовые.
Движение NOSQL
Исторически сложилось так, что большинство веб-приложений корпоративного уровня использует реляционные базы данных. Но в последнее десятилетие мы столкнулись с настолько большими объемами данных, которые так быстро меняются и так разнообразны по своей структуре, что с ними невозможно работать, используя традиционные реляционные СУБД. Движение NOSQL создано для решения этой проблемы.
Неудивительно, что количество хранимых данных резко возросло, и их объем стал основной движущей силой использования NOSQL- хранилищ. Объем можно определить просто как размер наборов хранимых данных.
Как известно, большие наборы данных очень сложно хранить в реляционных базах данных. В частности, время выполнения запросов увеличивается вместе с увеличением размеров таблиц и ростом числа соединений (так называемая болезнь соединений). И это не вина самих баз данных. Это один из аспектов, лежащий в основе модели данных, заключающийся в извлечении множества возможных результатов запроса с последующей их фильтрацией для получения лишь необходимых.
Чтобы избежать соединений и сопутствующих им болезней и тем самым улучшить обработку очень больших наборов данных, в NOSQL-мире предложено несколько альтернатив реляционной модели. Хотя они лучше справляются с обработкой очень больших наборов данных, эти альтернативные модели, как правило, менее наглядны, чем реляционная (за исключением графовой модели, которая является даже более наглядной).
Но объем – это не единственная проблема, с которой сталкиваются современные веб-системы. Помимо своего большого объема, современные данные обычно очень быстро изменяются. Скорость – это темп изменения данных с течением времени.
Скорость редко остается статичной. Внутренние и внешние изменения системы и контекста ее использования могут оказать значительное воздействие на скорость. В сочетании с большим объемом данных переменная скорость требует от хранилища не только справляться с устойчиво высоким уровнем объемов записи, но и оставаться работоспособным при пиковых нагрузках.
Существует еще один аспект скорости – скорость изменения структуры данных. Другими словами, вдобавок к изменению значений определенных свойств может меняться общая структура элементов, определяющих эти свойства. Это обычно происходит по двум причинам. Первой является динамизм прикладной области. При изменениях в прикладной области меняются и потребности в данных. Во- вторых, сбор данных часто является экспериментальным процессом. Некоторые свойства создаются «на всякий случай», другие добавляются позднее в связи с изменением требований. Те, что оказались нужными, остаются, прочие выбрасываются. Оба этих аспекта в реляционном мире вызывают проблемы, поскольку большой объем записи привносит высокие расходы обработки, а высокая изменчивость схем сопровождается высокими эксплуатационными затратами.
Хотя позднее на чашу весов были добавлены и прочие вполне обоснованные причины, но решающей причиной стало осознание, что данные гораздо более разнообразны, чем данные, с которыми обычно имеет дело реляционный мир. Существенным аргументом является мысль об обилии пустых значений в таблицах и проверок на существование значений в коде. А последние сомнения прогнало разнообразие, т. е. степень регулярности или нерегулярности структуры данных, плотность или разреженность, связанность или разделенность.
ACID или BASE
Первое знакомство с базами данных NOSQL часто происходит в хорошо знакомом контексте реляционных баз данных. Понятно, что данные и модели запросов будут другими (в конце концов, отсутствует поддержка SQL), но модели согласования данных, используемые NOSQL-хранилищами, также весьма отличаются от тех, что используются реляционными базами данных. Разные NOSQL-базы данных используют разные модели согласования для поддержки разных объемов, скоростей изменения и разнообразия данных, упомянутых выше.
Давайте рассмотрим, какие функции согласованности помогают обеспечить безопасность хранимых данных и какие компромиссы допускаются при использовании (большинства)
В мире реляционных баз данных общеизвестны ACID-транзакции, некоторое время являвшиеся эталоном. Гарантии ACID обеспечивают безопасную среду для обработки данных:
- атомарность (Atomic) – все операции в транзакции либо успешны, либо для всех них выполняется откат;
- согласованность (Consistent) – по окончании транзакции база данных является структурно согласованной;
- изолированность (Isolated) – транзакции не мешают друг другу. Спорные ситуации разрешаются базой данных так, что транзакции выполняются последовательно;
- долговечность (Durable) – результаты применения транзакции не должны теряться, даже при сбоях.
Эти свойства означают, что сразу по завершении транзакции ее данные согласуются (так называемая согласованность записи) и записываются на диск (или на диски, или в разные области памяти). Это отличная абстракция для разработчиков приложений, но требует сложных блокировок, которые могут вызвать логическую недоступность, и, как правило, считается излишне тяжеловесным шаблоном в подавляющем большинстве прикладных областей.
Для многих прикладных областей ACID-транзакции являются излишне пессимистичными. В мире NOSQL ACID-транзакции вышли из моды, поскольку хранилища смягчили требования к немедленной согласованности, актуальности данных и их точности, чтобы получить другие преимущества, такие как масштабируемость и гибкость. Вместо ACID возник другой популярный подход BASE, описывающий принципы более оптимистичной стратегии хранения:
- обычно доступно (Basicavailability) – хранилище доступно большую часть времени;
- гибкое состояние (Soft-state) – хранилища не обязаны соблюдать очередность записей, и разные реплики не должны постоянно согласовываться;
- отложенная согласованность (Eventualconsistency) – хранилища достигают согласованности с некоторой задержкой по времени (например, позже, во время чтения).
Принципы BASE значительно слабее гарантий ACID, и между ними нет прямого соответствия. Значения в BASE-хранилище доступны (потому что это является основой масштабирования), но это не предлагает гарантированной согласованности реплик при записи. BASE-хранилища обеспечивают менее строгий контроль: данные будут согласованы позднее, вероятнее всего, во время чтения (как, например, в Riak), или всегда будут согласованы, но только для определенных фиксаций, обработанных последними (как, например, в Datomic).
Разработчики должны учитывать такую свободную поддержку согласованности и уделять больше внимания согласованности данных. Им следует познакомиться с методами BASE конкретного хранилища и научиться работать в рамках его ограничений. На практике в каждом конкретном случае делается выбор, приемлема ли возможная противоречивость данных или же нужно потребовать от базы данных обеспечить непротиворечивость при чтении, согласившись с возникающими при этом задержками. (Чтобы гарантировать непротиворечивое чтение, базе данных необходимо сравнить все реплики элемента данных и в случае их несогласованности выполнить корректирующую обработку.) При разработке это добавляет сложностей, по сравнению с применением транзакций, которые берут на себя обязанности по достижению согласованности, но это не является неразрешимой проблемой, просто это требует дополнительных усилий.
Классификация и секторы NOSQL
Познакомившись с базовой моделью согласованности данных в NOSQL-хранилищах, можно перейти к рассмотрению использования многочисленных моделей данных. Для большей определенности нами разработана простая классификация, изображенная на рис. 1. Эта классификация делит современную область NOSQL на четыре сектора. Хранилища в каждом секторе предназначены для разных типов функционального применения, хотя и нефункциональные требования также могут сильно повлиять на выбор базы данных.
В следующих моих блогах будут отдельно рассмотрены каждый из этих секторов, особое внимание будет уделено характеристикам их моделей данных, особенностям их эксплуатации и побудительным причинам их выбора.
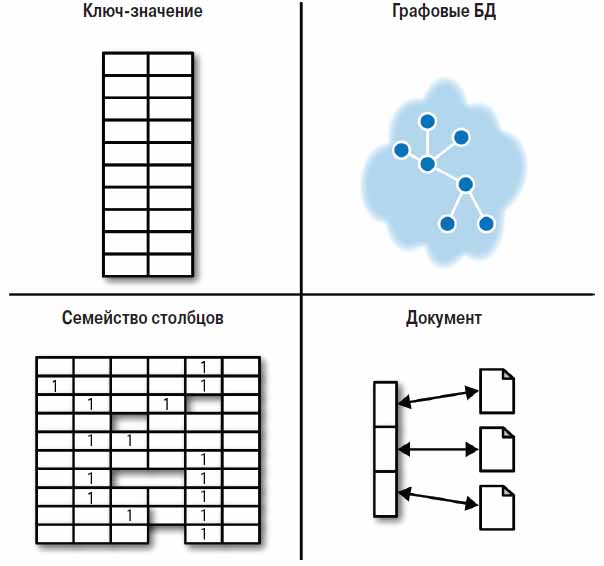
Рис. 1 Секторы NOSQL-хранилищ
Эволюция NoSQL, основные преимущества перед SQL
Нет сомнений в том, что методы работы веб-приложений с данными существенно изменились за последнее десятилетие. Собирается и используется всё больше данных, и всё больше пользователей одновременно получают доступ к этим данным. Это означает, что масштабируемость и производительность являются более сложной задачей, чем для реляционных баз данных, основанных на схеме, чьё масштабирование сложнее.
Проблема масштабируемости SQL была признана интернет-компаниями с огромными растущими потребностями в данных и инфраструктуре, такими как Google, Amazon и Facebook. Они придумали свои собственные решения проблемы – такие технологии, как BigTable, DynamoDB и Cassandra.
Этот растущий интерес привел к появлению ряда систем управления базами данных NoSQL (СУБД) с упором на производительность, надежность и согласованность. Ряд уже существующих структур индексирования был пересмотрен и усовершенствован с целью повышения производительности поиска и операций чтения.
Во-первых, существовали запатентованные (с закрытым исходным кодом) типы баз данных NoSQL, разработанные крупными компаниями для удовлетворения их конкретных потребностей, такие как Bigtable от Google, которая считается первой системой NoSQL, и DynamoDB от Amazon.
Успех этих проприетарных систем положил начало разработке ряда аналогичных систем баз данных с открытым исходным кодом и проприетарных систем, наиболее популярными из которых являются Hypertable, Cassandra, MongoDB, DynamoDB, HBase и Redis.
Что отличает NoSQL?
Одним из ключевых различий между базами данных NoSQL и традиционными реляционными базами данных является тот факт, что NoSQL является формой неструктурированного хранилища.

Это означает, что базы данных NoSQL не имеют фиксированной структуры таблиц, как в реляционных базах данных.
Преимущества NoSQL
Базы данных NoSQL имеют много преимуществ по сравнению с традиционными реляционными базами данных.
Одно из основных отличий заключается в том, что базы данных NoSQL имеют простую и гибкую структуру. Они не используют схем. В отличие от реляционных баз данных, базы данных NoSQL основаны на парах ключ-значение.
Некоторые типы хранилища NoSQL баз данных включают хранение столбцов, документов, значений ключей, графов, объектов, XML объектов и другие способы хранения данных.
Обычно каждое значение в базе данных обозначается ключом. Некоторые хранилища баз данных NoSQL также позволяют разработчикам хранить сериализованные объекты в базе данных, а не только простые строковые значения.
Базы данных NoSQL с открытым исходным кодом не требуют покупки дорогостоящей лицензии и могут работать на недорогом оборудовании, что делает их развертывание экономически эффективным.
Кроме того, при работе с базами данных NoSQL, независимо от того, являются ли они открытыми или проприетарными, масштабирование осуществляется проще и дешевле, чем при работе с реляционными базами данных. Это происходит потому, что расширение происходит в горизонтальном направлении и нагрузка распределяется на все узлы, а не по типу вертикального масштабирования, характерном для реляционных баз данных, где увеличение производительности достигается апгрейдом хоста на более мощный.
Недостатки NoSQL баз данных
Конечно, базы данных NoSQL не идеальны, и они не всегда могут использоваться в качестве систем хранения данных.
Во-первых, большинство баз данных NoSQL не заточены на надёжность в той мере, в которой это относится к традиционным базам данных. Такие характеристики как атомарность, консистентность, изоляция и стойкость данных в системах NoSQL принесены в жертву производительности и масштабируемости.
Для поддержки функций надежности и согласованности разработчикам необходимо реализовать собственный проприетарный код, что усложняет работу системы. Это ограничивает использование NoSQL в областях, где важна безопасность и надёжность транзакции, таких как банковские системы.
Так же NoSQL базы данных не совместимы с запросами SQL. Это означает, что необходимо вручную переписывать запросы для работы с этим типом баз данных.
NoSQL против реляционных баз данных
Давайте сравним NoSQL с обычной базой данных:

