Микросервисы для Java программистов. Практическое введение во фреймворки и контейнеры
Soft, интернет, безопасность: новости, статьи, советы, работа
Избранное сообщение
Фетісов В. С. Комп’ютерні технології в тестуванні. Навчально-методичний посібник. 2-ге видання, перероблене та доповнене / Мои публикации
В 10-х годах я принимал участие в программе Европейского Союза Tempus “Освітні вимірювання, адаптовані до стандартів ЄС”. В рамк.
вторник, 31 октября 2017 г.
Микросервисы для Java программистов. Практическое введение во фреймворки и контейнеры. (Часть 3) / Программирование на Java
Перевод книги Кристиана Посты (Christian Posta) Microservices for Java Developers. A Hands-On Introduction to Frameworks & Containers. Продолжение. Предыдущая публикация.
ГЛАВА 1. Микросервисы для Java программистов
(Продолжение)
Проектирование с учетом обязательств
В среде микросервисов с автономными командами и сервисами очень важно иметь в виду взаимоотношения между поставщиком и потребителем сервиса. Как автономная команда обслуживающая сервис, Вы не можете предъявлять какие-либо требования к другим командам и сервисам потому, что Вы не владеете ими, они автономны по определению. Всё, что Вы можете сделать — это выбрать, будете ли Вы принимать или не принимать их обязательства функциональности или поведения. А как поставщик сервиса для других, всё, что Вы можете сделать — это пообещать им определенное поведение. Они вольны в выборе — доверять Вам или нет. Модель теории обязательств впервые предложена Марком Берджессом (Mark Burgess) в 2004 году и описана в его книге «В поисках определенности» (In Search of Certainty, O’Reilly, 2015). Это исследование автономных систем включая человеческие и компьютерные, оказывающие услуги друг другу.
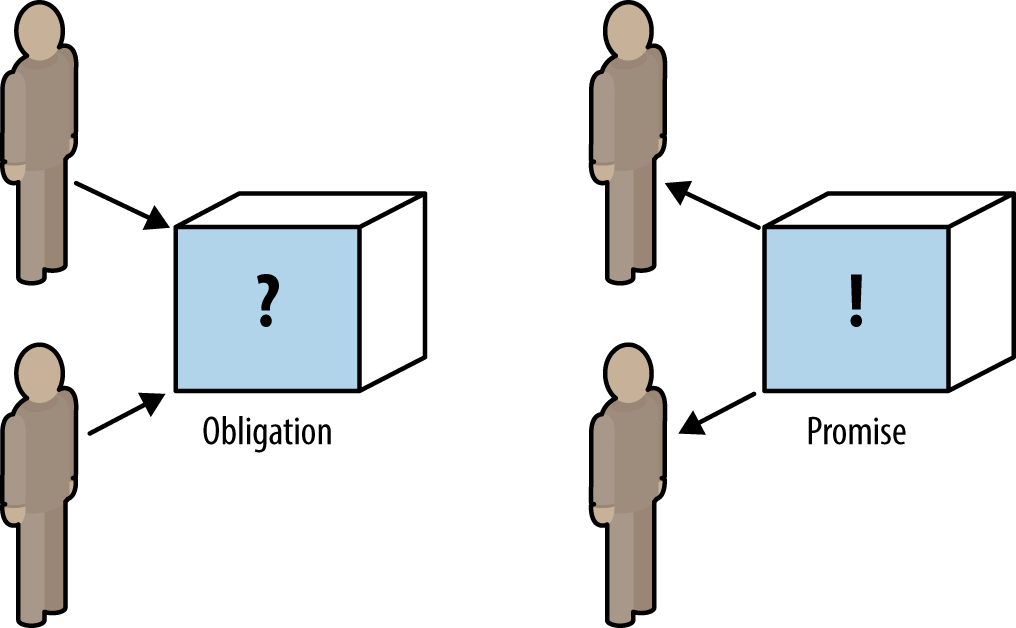
С точки зрения распределенных систем «обязательство» помогает сформулировать, какие услуги предоставляются и какие предположения на их счет могут или не могут быть сделаны. Например, команда владеет сервисом, который рекомендует книги. Мы обещаем персонифицированный набор книг, рекомендуемый для конкретного произвольного пользователя. Что произойдет, если при обращении к этому сервису один из бэкендов (база данных, хранящая текущий профиль рекомендаций для пользователей) вдруг недоступен? Мы могли бы сгенерировать исключение и отправить обратно трассировку стека, но это было бы не очень приятно для потребителя и может потенциально развалить другие части системы. Мы дали обещание и мы попытаемся сделать всё возможное, чтобы выполнить его. В том числе вернув некий стандартный набор рекомендаций книг или подмножество, состоящее из любой книги. Бывают случаи, когда обещания невозможно выполнить и наилучшее поведение в таком случае будет определяться уровнем сервиса или результатом для пользователей, который мы хотели бы сохранить. Ключевым здесь является акцент на обещании сервиса (выдать рекомендации), даже если сервис от которого мы зависим, не может выполнить своё обещание (база данных отказала). Попытки сдержать обещание помогают сохранить остальные части системы и удержать уровень качества обслуживания.
Другой взгляд на «обязательство» — это согласованное взаимное понимание его ценности для обеих сторон (как производителя, так и потребителя). Но как же нам выбрать из двух поставщиков, что ценнее и на какие обязательства нам стоит соглашаться? Если никто не обращается к сервису или не получает результат от обещаний, чем полезен такой сервис? Один из способов сформулировать обязательства между потребителями и поставщиками — это задаваемый потребителем контракт (consumer-driven contract). В задаваемом потребителем контракте мы можем зафиксировать объем обещаний кодом или утверждениями, а в качестве поставщика мы можем использовать эти знания, чтобы проверить, действительно ли мы держим свои обещания.
Управление распределенными системами
В конце концов управление отдельной системой проще, чем распределенной. Если есть только одна машина, один сервер приложений и в системе случились проблемы, мы знаем где искать. Если нужно изменить конфигурацию, обновить до определенной версии или обезопасить его — это всё равно одно физическое и логическое расположение. Выполнять управление, отладку и изменения в таком случае достаточно просто. Единая система может работать для некоторых приложений, но там, где требуется масштабирование, следует обратить внимание на микросервисы. Как мы уже упоминали ранее, микросервисы не даются бесплатно — плата за гибкость и масштабируемость — более сложная система управления.
Вот некоторые вопросы управляемости развертывания микросервисов:
- Как запускать и останавливать весь «флот» сервисов?
- Как собирать и консолидировать логи/метрики/параметры качества со всех микросервисов?
- Как обнаруживать сервисы в изменяющемся окружении, если они могут появляться, исчезать, перемещаться и т.п.?
- Как осуществлять балансировку нагрузки?
- Как мы получим состояние кластера или отдельных микросервисов?
- Как перезапустить «упавшие» сервисы?
- Как организовать настраиваемую маршрутизацию запросов API?
- Как обеспечить безопасность сервисов?
- Как придержать/разогнать или отключить части кластера если он начал «разваливаться» или вести себя непредсказуемо?
- Как развернуть несколько версий сервиса и корректно маршрутизировать к ним запросы?
- Как провести изменения конфигурации во всем «флоте» сервисов?
- Как организовать изменение кода приложения и его конфигурации безопасным, проверяемым и повторяемым способом?
И это не самые легкие для решения проблемы. Остальная часть книги будет посвящена введению Java-разработчиков в мир микросервисов и в способы решения некоторых из перечисленных выше проблем. Полный, всеобъемлющий перечень инструкций и ответов на перечисленные вопросы (и многие другие) появится во втором издании этой книги.
Технологические решения
На протяжении остальной книги мы познакомим Вас с некоторыми популярными компонентами технологий и как они решают некоторые проблемы разработки и внедрения программного обеспечения с использованием архитектуры микросервисов. Как говорилось ранее, микросервисы — это не только технологическая проблема, первостепенными являются правильная организационная структура и соответствующие команды. Переход от SOAP к REST не создает микросервисную архитектуру.
Первым шагом для команды Java разработчиков разрабатывающей микросервисы, является получение работающего результата на своей локальной машине! Эта книга познакомит Вас с тремя фреймворками Java для работы с микросервисами: Spring Boot, Dropwizard и WildFly Swarm. Каждый из них имеет свои плюсы для разных команд, организаций и подходов к микросервисам. Так же как и для любой другой технологии то, что некоторые инструменты лучше подходят для той или иной работы или команды — это норма. Перечисленные инструменты не единственные в своем роде. Есть еще пара, которые исповедуют реактивный подход к микросервисам — это Vert.x и Lagom. Переход к событийной модели разработки слегка отличается и требует несколько другого набора знаний, так что в этой книге мы будет придерживаться модели, которую большинство Java программистов найдут вполне комфортной.
Цель этой книги — подготовить Вас к использованию основных возможностей каждого из фреймворков. Мы погрузимся в пару «продвинутых» концепций в последней главе, но для первых шагов с каждым из фреймворков мы будем использовать микросервисное приложение «hello-world». Эта книга не является всеобъемлющим справочником по разработке микросервисов. В каждом разделе есть ссылки на справочные материалы, которые Вы сможете изучить по мере необходимости. Мы будем постепенно развивать приложение «hello-world», создав несколько сервисов и демонстрируя различные простые схемы взаимодействия.
Заключительный этюд для каждого из фреймворков затронет такие концепции как «переборки» (bulkheading) и «теория обязательств», чтобы сделать сервисы более устойчивыми перед лицом отказов. Мы покопаемся в таких частях стека NetflixOSS как Hystrix, что поможет облегчить реализацию этого функционала. Мы обсудим плюсы и минусы такого подхода и исследуем другие существующие варианты.
По мере продвижения по примерам мы обсудим значение Linux-контейнеров для развертывания, управления и изоляции микросервисов равно как и их значение для локальной разработки. Docker и Kubernetes внесли неоценимый вклад в упрощение работы с распределенными масштабируемыми системами, поэтому мы обсудим некоторые полезные практики связанные с контейнерами и микросервисами.
В последнем разделе, мы дадим Вам несколько мыслей на тему управления распределенными конфигурациями, логированием, мониторингу и непрерывной поставки.
Подготовка среды разработки
Для примеров мы будем использовать Java 1.8 и собирать их с помощью Maven. Пожалуйста, убедитесь, что у Вас установлены соответствующие программы и выполнены следующие условия:
- JDK 1.8
- Maven 3.2+
- Есть доступ к командной строке (bash, PowerShell, cmd, Cygwin, и т.д.)
Экосистема Spring имеет несколько отличных инструментов, которые можно использовать либо в командной строке, либо в IDE. Большинство примеров будет придерживаться командной строки, чтобы оставаться независимыми от IDE потому, что каждая IDE определяет свой собственный способ работы с проектами. Для Spring Boot, мы будем использовать Spring Boot CLI 1.3.3.
Альтернативные IDE и инструментарий для Spring:
IDE на базе Eclipse: Spring Tool Suite.
Spring Initializr web interface.
И для Dropwizard, и для WildFly Swarm мы будем использовать JBoss Forge CLI и некоторые расширения, чтобы создавать и управлять проектами: JBoss Forge 3.0+.
Альтернативные IDE и инструментарий для проектов Spring, Dropwizard или WildFly Swarm (которые отлично работают с JBoss Forge):
- IDE на базе Eclipse: JBoss Developer Studio.
- Netbeans.
- IntelliJ IDEA.
И наконец, для сборки и запуска микросервисов в виде Docker-контейнеров внутри Kubernetes нам понадобятся следующие инструменты для развертывания среды контейнеров:
- Vagrant 1.8.1.
- VirtualBox 5.0.x.
- Container Development Kit 2.x.
- Kubernetes/Openshift CLI.
- Docker CLI (опционально).
Микросервисы для Java программистов. Практическое введение во фреймворки и контейнеры
Но другой пост сказал, что микросервисы плохие
Этот сабвуфер является микросервисным биполярным по-настоящему. Серьезно устаревшее сообщество
Черепаха считалась зайцем устаревшей.
Этот ответ бессмысленный и произвольный
Я бэкэнд, поэтому я ничего не знаю об этом. Я только что попробовал примеры докеров на днях в первый раз. Почти все на работе тоже сделано на заказ, поэтому у меня мало шансов научиться чему-либо подобному. У меня нет сильного желания изучать вещи ops, но я определенно должен учиться немного. Это будет здорово.
Как бэкэнд-разработчик, вы должны изучить этот материал, чтобы понять, как ваши приложения будут на самом деле запускаться – знание оперативных данных поможет вам в принятии дизайнерских решений. Честно говоря, это бесценное знание, которое должен знать любой бэкэнд-разработчик.
Полностью согласен, вероятно, младший или старый. Как будто мы перешли к точке запуска Java-приложений локально
Сейчас я не развертываюсь в контейнерах, поэтому у меня было мало причин узнать о них или использовать их. Вопросы производительности имеют тенденцию доминировать (особенно в системах с низкой задержкой). И ничто из того, над чем я работаю, не использует общедоступную облачную сеть.
Однако, безусловно, есть вариант использования для более зависимых от пропускной способности и автономных систем или тех, которые мы должны распределять идентичные узлы через сеть. Мне просто нужно потратить время, но всегда есть чему поучиться, и слишком часто ops отодвигает на второй план аппаратное обеспечение, сеть, новые эксперименты, бла-бла .
Я не понимаю, как меня понизили за комментарий «это поможет мне научиться». Действительно очень любопытно.
Я думаю, что люди, которые проголосовали против вас, были так сосредоточены на том, что «я бэкэнд, поэтому я ничего не знаю об этом», они не могли прочесть это.
Почему это то, с чем кто-то может поспорить? Это как люди смотрят. Вы видите, что кто-то делает что-то и удивляетесь, почему они это сделали.
потому что именно так RedDit работает, к сожалению (или, к счастью, к счастью?), люди будут принижать то, с чем они не согласны. в вашем случае
«Я бэкэнд, поэтому ничего об этом не знаю»
На мой взгляд, это «ложное» утверждение. если вы думаете, что работа в бэкэнде означает, что вы ничего не должны знать об архитектуре программного обеспечения, то вы очень не правы. лично я не сделал и редко понижать голос. но из-за вашего первоначального явно неверного утверждения я возьму все, что вы сказали, с 2 фунтами соли. другие люди просто понижают голос. разные штрихи
Ах, так ты прыгаешь по всему слову “так”?
Я просто имел в виду это как описание меня. Моя конкретная область разработки (высокая производительность и чувствительность к задержке) не использует vms или контейнеры в ряде областей из-за соображений производительности (в основном связанных с io).
Это утверждение, которое вы называете «явно ложным», верно для многих из нас, от встроенных до высокопроизводительных распределенных сетей. Я разработал всю торговую систему, и это просто не та технология, которую я когда-либо имел в ней использовать. Есть другие места на периферии, которые, кажется, будут полезны, но это не моя рубка. Мы также склонны писать много вещей по дому по разным причинам и делать довольно низкоуровневые вещи, так что это мешает мне узнавать о них.
вся торговая система
какие инструменты? Много ли в вашей истории сообщений о вашей работе с Java, потому что я бы хотел ее прочитать.
В основном акции и фьючерсы, некоторые FX, некоторые фиксированные. Я не думаю, что моя история сообщений содержит много чего-нибудь подобного. Я мог бы ответить на несколько вопросов здесь или там о переполнении стека и связанных сайтах. Может быть, несколько твитов (почему-то производительность Java повсюду в Twitter).
Большая часть работы на Java довольно низкого уровня и много переписывается, чтобы избежать проблем с сборкой мусора и заставить HotSpot генерировать хороший код (требуется некоторая разборка). Я думаю, что эти системы похожи на гоночные автомобили серийных автомобилей: снаружи они выглядят как обычные системы Java, но внутри они совершенно другие и полностью отделаны.
Если бы такие вещи, как докер, не имели никакого эффекта задержки, их было бы здорово использовать в более широком диапазоне. Если бы все аспекты безопасности Docker были удалены, это могло бы быть ноль накладных расходов?
Есть ли у вас какие-либо рекомендации в блоге, которые охватывают темы Java и трейдинга?
Ах, так ты прыгаешь по всему слову “так”?
Ну, да, это предложение звучит так, как если бы пользователи не должны были знать архитектуру или быть знакомыми с ней. Круто, что у вас есть весь этот опыт, но ваш домен отличается, и, возможно, что-то вроде «я мало работал с этими технологиями из-за работы в другом домене, поэтому я не знаю много об этом» были более точными
может быть, что-то вроде «я не очень много работал с этими технологиями из-за работы в другой области
Я считаю, что это то, что я сказал:
Почти все на работе тоже сделано на заказ, поэтому у меня мало шансов научиться чему-либо подобному. . Я определенно должен учиться немного. Это будет здорово.
Я не могу поверить, что люди были так взорваны из-за такой крошечной вещицы.
clothes_are_optional ответил на него довольно хорошо
Потому что людям нравится конфликт, когда он анонимный. Это заставляет их чувствовать себя сильными в атаке, когда нет риска контратаки.
В вашем случае, они взяли ваши слова, чтобы означать, что разработчик не должен знать об операциях. Конечно, это совсем не то, что вы сказали или даже подразумевали, но это не имеет значения для людей, которые просто любят размешивать горшок.
Или, некоторые люди на законных основаниях не имеют навыков чтения. Это всегда возможно.
Просто катись с этим. Меня опускают до дерьма, когда я открываю рот в подпрограмме Javascript, если осмелюсь хотя бы немного / сорта / возможно / слегка оспорить то, что сообщество считает лучшим. Я думаю, что некоторые люди не любят других, которые ставят под сомнение их знания либо.
Полагаю, сделайте свой выбор: противники, плохие читатели или неуверенные люди. Может быть смесь тоже 🙂
«Микросервисная архитектура (MSA) – это подход к построению программных систем, который разбивает модели бизнес-доменов на более мелкие, согласованные, ограниченные контексты, реализуемые сервисами».
Итак . услуги. SOA. Что такое “Микросервис” на самом деле? Новое модное слово.
Этот пост сегодня является одним из двух для Орейли. Это действительно просто СПАМ.
Нет нет нет. Это не SOA. Эта архитектура похожа на концепцию SOA, но отличается по реализации. SOA зависит от тупых конечных точек и умных каналов. Микросервисы зависят от умных конечных точек и тупых каналов. Разница может не показаться вам большой, но для всех, кто помнит программирование для ESB, разница огромна.
Не могли бы вы рассказать о тупых / умных + конечных точках / трубах?
Конечно. В SOA у вас были умные каналы, термин, который относится к каналам, которые не просто обеспечивают соединение. В SOA эти каналы были известны как корпоративная сервисная шина (ESB). Они будут направлять данные в зависимости от их содержимого, а также выполнять вычисления и преобразования данных на лету. Затем конечные точки будут обрабатывать данные, отправлять их обратно в ESB, который снова будет определять маршрутизацию и конечную точку и выполнять предварительно запрограммированные преобразования данных и т. Д.
В микросервисах трубы ничего не определяют. В основном это просто JSON через HTTP. Конечные точки определяют, куда будут отправлены данные, а любые преобразования или операции выполняются конечными точками, а не ESB.
Надеюсь, это поможет!
Это SOA. Сервисная шина предприятия теперь просто распределена по общим библиотекам, балансировщикам нагрузки, оркестровщикам контейнеров и т. Д. И мыло xml заменено на json. Концептуально ничего особенного не изменилось.
Умные конечные точки – тупые трубы, умные трубы – тупые конечные точки. Это фигня. Маркетинг. Трубы – это трубы, они не умны и не глупы.
Учимся разворачивать микросервисы. Часть 1. Spring Boot и Docker
Категории
Свежие записи
Наши услуги

В этой статье я хочу рассказать о своем опыте создания учебной среды для экспериментов с микросервисами. При изучении каждого нового инструмента мне всегда хотелось его попробовать не только на локальной машине, но и в более реалистичных условиях. Поэтому я решил создать упрощенное микросервисное приложение, которое впоследствии можно будет “обвешивать” всякими интересными технологиями. Основное требование к проекту — его максимальная функциональная приближенность к реальной системе.
Изначально я разбил создание проекта на несколько шагов:
Создать два сервиса — ‘бекенд’ (backend) и ‘шлюз’ (gateway), упаковать их в docker-образы и настроить их совместную работу
Ключевые слова: Java 11, Spring Boot, Docker, image optimization
Ключевые слова: Kubernetes, GKE, resource management, autoscaling, secrets
Создание чарта с помощью Helm 3 для более эффективного управления кластером
Ключевые слова: Helm 3, chart deployment
Настройка Jenkins и пайплайна для автоматической доставки кода в кластер
Ключевые слова: Jenkins configuration, plugins, separate configs repository
Каждому шагу я планирую посвятить отдельную статью.
Направленность этого цикла статей заключается не в том, как написать микросервисы, а как заставить их работать в единой системе. Хоть все эти вещи обычно лежат за пределами ответственности разработчика, думаю, что все равно полезно быть знакомым с ними хотя бы на 20% (которые, как известно, дают 80% результата). Некоторые безусловно важные темы, такие как обеспечение безопасности, будут оставлены за скобками этого проекта, так как автор в этом мало что понимает система создается исключительно для личного пользования. Я буду рад любым мнениям и конструктивной критике.
Создание микросервисов
Сервисы были написаны на Java 11 с использованием Spring Boot. Межсервисное взаимодействие организовано с использованием REST. Проект будет включать в себя минимальное количество тестов (чтобы потом было, что тестировать в Jenkins). Исходный код сервисов доступен на GitHub: бекенд и шлюз .
Чтобы иметь иметь возможность проверить состояние каждого из сервисов, в их зависимости был добавлен Spring Actuator. Он создаст эндпойнт /actuator/health и будет возвращать 200 статус, если сервис готов принимать траффик, или 504 в случае проблем. В данном случае это довольно фиктивная проверка, так как сервисы очень просты, и при каком-то форсмажоре они скорее станут полностью недоступны, чем сохранят частичную работоспособность. Но в реальных системах Actuator может помочь диагностировать проблему до того, как об нее начнут биться пользователи. Например, при возникновении проблем с доступом к БД, мы сможем автоматически на это среагировать, прекратив обрабатывать запросы сломанным экземпляром сервиса.
Сервис Backend
Сервис бекенда будет просто считать и отдавать количество принятых запросов.
Тест на контроллер:
Сервис Gateway
Шлюз будет переадресовывать запрос сервису бекенда, дополняя его следующей информацией:
- id шлюза. Он нужен, чтобы можно было по ответу сервера отличить один экземпляр шлюза от другого
- Некий “секрет”, который будет играть роль очень важного пароля (№ ключа шифрования важной куки)
Конфигурация в application.properties:
Адаптер для связи с бекендом:
Запуск:
Все работает. Внимательный читатель отметит, что нам ничего не мешает обратиться к бекенду напрямую в обход шлюза ( http://localhost:8081/requests ). Чтоб это исправить, сервисы должны быть объединены в одну сеть, а наружу “торчать” должен только шлюз.
Также оба сервиса делят одну файловую систему, плодят потоки и в один момент могут начать мешать друг другу. Было бы неплохо изолировать наши микросервисы. Этого можно достичь с помощью разнесения приложений по разным машинам (много денег, сложно), использования виртуальных машин (ресурсоемко, долгий запуск) или же с помощью контейнеризации. Ожидаемо выбираем третий вариант и Docker как инструмент для контейнеризации.
Docker
Если вкратце, то докер создает изолированные контейнеры, по одному на приложение. Чтобы использовать докер, требуется написать Dockerfile — инструкцию по сборке и запуску приложения. Далее можно будет собрать образ, загрузить его в реестр образов (№ DockerHub ) и в одну команду развернуть свой микросервис в любой докеризированной среде.
Dockerfile
Одна из важнейшей характеристик образа — это его размер. Компактный образ быстрее скачается с удаленного репозитория, займет меньше места, и ваш сервис быстрее стартует. Любой образ строится на основании базового образа, и рекомендуется выбирать наиболее минималистичный вариант. Хорошим вариантом является Alpine — полноценный дистрибутив Linux с минимумом пакетов.
Для начала попробуем написать Dockerfile “в лоб” (сразу скажу, что это плохой способ, не делайте так):
Здесь мы используем базовый образ на основе Alpine с уже установленным JDK для сборки нашего проекта. Командой ADD мы добавляем в образ текущую директорию src, отмечаем ее рабочей (WORKDIR) и запускаем сборку. Команда EXPOSE 8080 сигнализирует докеру, что приложение в контейнере будет использовать его порт 8080 (это не сделает приложение доступным извне, но позволит обратиться к приложению, например, из другого контейнера в той же сети докера).
Чтобы упаковать сервисы в образы надо выполнить команды из корня каждого проекта:
В результате получаем образ размером в 456 Мбайт (из них базовый образ JDK 340 занял Мбайт). И все притом, что классов в нашем проекте по пальцем пересчитать. Чтобы уменьшить размер нашего образа:
- Используем многошаговую сборку. На первом шаге соберем проект, на втором установим JRE, а третим шагом скопируем все это в новый чистый Alpine образ. Итого в финальном образе окажутся только необходимые компоненты.
- Воспользуемся модуляризацией java. Начиная с Java 9, можно с помощью инструмента jlink создать JRE только из нужных модулей
Для любознательных, вот хорошая статья про подходы уменьшения размеров образа https://habr.com/ru/company/ruvds/blog/485650/ .
Пересоздаем образ, и он в итоге похудел в 6 раз, составив 77 МБайт. Неплохо. После, готовые образы можно загрузить в реестр образов, чтобы ваши образы были доступны для скачивания из интернета.
Совместный запуск сервисов в Docker
Для начала наши сервисы должны быть в одной сети. В докере существует несколько типов сетей, и мы используем самый примитивный из них — bridge, позволяющий объединять в сеть контейнеры, запущенные на одном хосте. Создадим сеть следующей командой:
Далее запустим контейнер бекенда с именем ‘backend’ с образом microservices-backend:1.0.0:
Стоит отметить, что bridge-сеть предоставляет из коробки service discovery для контейнеров по их именам. То есть сервис бекенда будет доступен внутри сети докера по адресу http://backend:8080 .
В этой команде мы указываем, что мы пробрасываем 80 порт нашего хоста на 8080 порт контейнера. Опции env мы используем для установки переменных среды, которые автоматически будут вычитаны спрингом и переопределят свойства из application.properties.
После запуска вызываем http://localhost/ и убеждаемся, что все работает, как и в прошлом случае.
Заключение
В итоге мы создали два простеньких микросервиса, упаковали их в докер-контейнеры и совместно запустили на одной машине. У полученной системы, однако, есть ряд недостатков:
- Плохая отказоустойчивость — у нас все работает на одном сервере
- Плохая масштабируемость — при увеличении нагрузки было бы неплохо автоматически разворачивать дополнительные экземпляры сервисов и балансировать нагрузку между ними
- Сложность запуска — нам понадобилось ввести как минимум 3 команды, причем с определенными параметрами (это только для 2 сервисов)
Для устранения вышеперечисленных проблем существует ряд решений, таких как Docker Swarm, Nomad, Kubernetes или OpenShift. Если вся система будет написана на Java можно посмотреть в сторону Spring Cloud ( хорошая статья ).
В следующей части я расскажу про то, как я настраивал Kubernetes и деплоил проект в Google Kubernetes Engine.