

Зачем нужна денормализация баз данных, и когда ее использовать
Нормализация баз данных простыми словами
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о нормализации базы данных, узнаем, что это такое, какие нормальные формы базы данных существуют и зачем вообще проводить нормализацию базы данных.

Постоянные посетители данного сайта знают, что я здесь публикую достаточно много различных материалов, связанных с языком SQL и системами управления базами данных, однако статей, связанных с теорией баз данных, на текущий момент, к сожалению, нет, поэтому я решил это исправить, и начать цикл статей, посвященных теории баз данных.
Начну я с нормализации баз данных. В этом материале мы поговорим в целом о процессе нормализации, узнаем, зачем проводить нормализацию базы данных, что такое нормальная форма базы данных, а также какие нормальные формы существуют. В следующих материалах я подробно и с примерами расскажу про каждую нормальную форму.
Реляционная база данных
В целом под базой данных можно понимать любой набор информации, которую можно найти в этой базе данных и воспользоваться ей, однако если говорить в контексте SQL, то речь будет идти, конечно, о реляционных базах данных, а что же это такое?
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями.
Логически такая база данных представлена в виде таблиц, в которых и лежит вся эта информация.
Примечание! Если Вас интересует язык SQL, рекомендую пройти мой онлайн-курс по основам SQL, который ориентирован на изучение SQL как стандарта, таким образом, Вы сможете работать в любой системе управления базами данных. Курс включает много практики: онлайн-тестирование, задания и многое другое.
Нормализация баз данных
В реляционных базах данных есть такое понятия, как «Нормализация».
Нормализация – это процесс удаления избыточных данных.
Также нормализацию можно рассматривать и с позиции проектирования базы данных, в таком случае мы можем сформулировать определение нормализации следующим образом.
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Зачем нормализовать базу данных?
У Вас может возникнуть вопрос – а зачем вообще нормализовать базу данных и бороться с этой избыточностью?
Дело в том, что избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным. Отсюда можно сделать вывод, что нормализация нужна для:
- Устранения аномалий
- Повышения производительности
- Повышения удобства управления данными
Теперь давайте поговорим о самой избыточности данных, что же это такое.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Так как в этом случае необходимо добавлять, изменять или удалять одни и те же данные в нескольких местах. Например, если не выполнить операцию в каком-нибудь одном месте, то возникает ситуация, когда одни данные не соответствуют вроде как точно таким же данным в другом месте.
Давайте рассмотрим пример. Допустим, у нас есть следующая таблица, она хранит информацию о предметах мебели, в частности наименование предмета и материал, из которого изготовлен этот предмет.
А теперь допустим, что у нас возникла необходимость подкорректировать название материала, вместо «Массив дерева» нужно написать «Натуральное дерево», и чтобы это сделать нам необходимо внести изменения сразу в несколько строк, так как предметов, изготовленных из массива дерева, несколько, а именно 2: стол и шкаф.
А теперь представьте, что по каким-то причинам мы внесли изменения только в одну строку, в итоге в нашей таблице будет и «Массив дерева», и «Натуральное дерево».
Какое из этих названий будет правильным? А если представить, что мы можем внести еще какое-то новое значение при добавлении новых записей, например, просто «Дерево».
В этом случае в нашей таблице в скором времени будет и «Массив дерева», и «Натуральное дерево», и просто «Дерево», и вообще, что угодно, ведь это просто текст.
Однако по своей сути это один и тот же материал, мы просто решили или подкорректировать его название, или ошиблись при добавлении новой записи. Это и есть аномалия, когда одни данные в одном месте не соответствуют вроде как точно таким же данным в другом месте. Это всего лишь один вид аномалии, однако в процессе добавления, изменения и удаления данных может возникать много других противоречивых ситуаций, т.е. аномалий.
При этом, обязательно стоит отметить, что в нашей таблице всего 5 записей, а теперь представьте, что их миллион!
Именно поэтому мы должны устранять избыточность данных в базе, т.е. проводить так называемую нормализацию базы данных.
В данном конкретном случае мы должны название материала, из которого изготовлены предметы мебели, вынести в отдельную таблицу, а в таблице с предметами сделать всего лишь ссылку на нужный материал, тем самым, соотнеся эту ссылку с исходной записью, мы будем понимать, из какого материала сделан тот или иной предмет.
Материалы, из которых изготовлены предметы мебели.
В этом случае когда нам потребуется изменить название материала, мы будем вносить изменение только в одном месте, т.е. править только одну строку.
Таким образом, представляя материалы в виде отдельной сущности и создавая для нее отдельную таблицу, мы устраняем описанную выше аномалию.
Другими словами, каждая сущность должна храниться отдельно, а в случае необходимости использования этой сущности в другой таблице на нее делается всего лишь ссылка, т.е. выстраивается связь.
Нормальные формы базы данных
В целом процесс нормализации базы данных выглядит следующим образом: мы, следуя определённым правилам и соблюдая определенные требования, проектируем таблицы в базе данных.
При этом все эти правила и требования можно сгруппировать в несколько наборов, и если спроектировать базу данных с соблюдением всех правил и требований, которые включаются в тот или иной набор, то база данных будет находиться в определённом состоянии, т.е. форме, и такая форма называется нормальная форма базы данных.
Иными словами, следуя определённым правилам и соблюдая определенные требования мы приводим базу данных к определенной нормальной форме.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Каждая следующая нормальная форма содержит более строгие правила и критерии, тем самым приводя базу данных к определённой нормальной форме мы устраняем определённый набор аномалий.
Отсюда можно сделать вывод, что чем выше нормальная форма, тем меньше аномалий в базе будет.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Иными словами, процесс перехода от одной нормальной формы к следующей – это усовершенствование базы данных. Так как если база данных находится в какой-то определённой нормальной форме – это означает, что в базе данных отсутствует определенный вид аномалий.
Существует 5 основных нормальных форм базы данных:
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
Однако выделяют еще дополнительные нормальные формы:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Нормальная форма Бойса-Кодда (BCNF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Если объединить оба этих списка и упорядочить нормальные формы от менее нормализованной до самой нормализованной, т.е. начиная с формы, при которой база данных по своей сути не является нормализованной, и заканчивая самой строгой нормальной формой, то мы получим следующий перечень:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
База данных считается нормализованной, если она находится как минимум в третьей нормальной форме (3NF).
В реальном мире нормализация до третьей нормальной формы (3NF) является обычной, стандартной практикой, так как 3NF устраняет достаточное количество аномалий, при этом производительность базы данных, а также удобство ее использования не снижается, что нельзя сказать о всех последующих формах.
Ситуации, при которых требуется нормализовать базу данных до четвертой нормальной формы (4NF), в реальном мире встречаются достаточно редко.
Если говорить о всех последующих нормальных формах (5NF, DKNF, 6NF), то в реальной жизни трудно даже представить ситуации, при которых потребуется нормализовать базу данных до этих форм.
Иными словами, 5NF, DKNF, 6NF – это в большей степени теоретические нормальные формы, немного отстраненные от реального мира.
Стоит отметить, что приведение базы данных к какой-то конкретной нормальной форме, обязательно требует, чтобы эта база данных уже находилась в предыдущей нормальной форме. Другими словами, если Вы хотите нормализовать базу данных до третьей нормальной формы, то база уже должна находиться во второй нормальной форме, т.е. нельзя нормализовать базу данных до третьей формы, если она еще не нормализована до второй.
Описание нормальных форм базы данных
В следующих статьях представлено подробное описание каждой нормальной формы и приведены примеры.
Примечание! Материалы находятся в работе, поэтому ссылки на статьи будут добавляться по мере готовности, поэтому следите за выходом новых статей в моих группах в социальных сетях: ВКонтакте, Facebook, Одноклассники, Twitter и Tumblr. Подписывайтесь, и Вы не пропустите выход нового материала!
На сегодня это все, надеюсь, материал был Вам полезен и интересен, пока!
Нормализация и денормализация базы данных, нормальные формы
 Нормализация схемы реляционной БД оказывает существенное влияние буквально на все аспекты взаимодействия с БД: от затрат на модификацию структур и данных до производительности запросов приложений и хранимых объёмов информации. В ряде случаев структуры могут быть сознательно денормализованы, что созвучно с другим словом «деморализованы». Однако, следует хорошо понимать, с какой целью это было сделано и полностью отдавать себе отчёт о последствиях. В общем же случае безопаснее всего придерживаться простого правила:
Нормализация схемы реляционной БД оказывает существенное влияние буквально на все аспекты взаимодействия с БД: от затрат на модификацию структур и данных до производительности запросов приложений и хранимых объёмов информации. В ряде случаев структуры могут быть сознательно денормализованы, что созвучно с другим словом «деморализованы». Однако, следует хорошо понимать, с какой целью это было сделано и полностью отдавать себе отчёт о последствиях. В общем же случае безопаснее всего придерживаться простого правила:
Нормализация — не догма, но чтобы её нарушать, нужны основания
На практике проектирования схем баз данных достижение третьей нормальной формы (3НФ) считается достаточным условием для большинства случаев.
Чему служат нормальные формы проще всего понять на примерах .
1НФ – первая нормальная форма
Первая нормальная форма (1НФ) выполняется, если все значения атрибутов (читай, колонок таблицы) атомарны, то есть неделимы.
Собственные типы данных СУБД считаются атомарными, исключение могут составлять массивы, в том числе символьные (текстовые) и байтовые. Следует также понимать, что атомарность может быть относительна выбранного взгляда со стороны предметной области и контекста. Например, телефонный номер в базе данных маркетинга содержится в одной колонке, тогда как у телефонных операторов он разделяется на номера АТС, шлейфов и т.п. Колонки для хранения комментариев, подлежащих последующей обработке приложением, также отчасти нарушают принцип атомарности.
По этой же причине не стоит рассматривать отдельно целую и дробные части действительного числа или даже пару «дата-время»: дальнейшая детализация не имеет смысла с точки зрения моделируемой области, где они атомарны.
Предположим, мы нарушили 1НФ и стали хранить фамилии, имена и отчества клиентов в одной колонке. Пока операторы вносили информацию, эта ошибка проектирования особенно не мешала, Однако, на следующем этапе понадобилась отчётность, в которой ФИО клиентов выводились бы в виде фамилии и инициалов. Оказалось, что некоторые записи вместо «Сидоров Петр Иванович» содержат «Петр Иванович Сидоров», в других отчества нет вовсе, в третьих фамилия двойная и не всегда записана через тире, в четвёртых после фамилий расставлены запятые. Эту проблему пришлось решать программированием совсем нетривиальной логики с элементами распознавания по словарю. Было потрачено много времени и средств, но в отчётности нет-нет да и проскакивали непонятные значения типа «Оглы П.Б.Б.».
Следует отметить, что при добавлении к этому учёту клиентов- иностранцев, проектировщиков логической схемы БД не спасла бы и более структурированная форма из трёх колонок для раздельного хранения фамилий, имён и отчеств. Потому что это проблема уровня концептуального проектирования и соответствующих моделей: необходим синтез не привязанной к модели данных структуры, способной вмещать в себя комбинации имён людей разных стран и культур.
2НФ – вторая нормальная форма
Вторая нормальная форма (2НФ) означает, что выполнены требования 1НФ, при этом все атрибуты целиком зависят от составного ключа и не зависят ни от какой его части.
На первый взгляд кажется, что нарушения 2НФ практически невозможны, потому что чаще всего в качестве первичных ключей используются автоинкрементные целочисленные значения или иные суррогаты для реализации ссылок. Однако, в определении говорится о ключах вообще, а не только о первичных. В отношении может быть несколько ключей, и некоторые из них могут являться составными. Такие ключи следует подвергнуть проверке в первую очередь.
Ассоциативная таблица — таблица, имеющая ключевые связи с двумя и более таблицами
Например, если каждая операция сбыта мебельной продукции в таблице продаж однозначно характеризуется колонками идентификатора товарной позиции, даты продажи и идентификатором покупателя, то нахождение в той же таблице столбца «Тип материала», зависящего непосредственно от товарной позиции, должно немедленно привлечь ваше внимание.
Аномалия в данном случае приведёт только к избыточности хранения в виде размера идентификатора, помноженного на число строк таблицы (без учёта индексов). Но если в той же таблице обнаружится ещё и колонка «Контактный телефон», присущая атрибутике покупателя, то последствия окажутся более серьёзными. Кроме избыточности хранения при ошибке ввода придётся исправлять номер телефона во всех записях о продажах данному покупателю.
Кроме приведённых примеров, при наличии в таблицах нескольких ключей необходимо, с позиций логики предметной области, определить, являются ли эти ключи присущими данной сущности или же они суть внешние ключи другой сущности, пока ещё не выделенной в процессе проектирования.
3НФ – третья нормальная форма
Третья нормальная форма (3НФ) означает, что выполнены требования 2НФ, при этом в между атрибутами отношения нет транзитивных зависимостей.
Что такое транзитивная зависимость легко понять на примере уже упоминавшейся выше таблицы продаж — типичного примера ассоциативной таблицы.
Предположим, что продажа каждой товарной позиции имеет своим основанием документ (заказ, счёт и т.д.), а её стоимость характеризуется ценой, количеством и валютой. В этом случае имеем следующие зависимости между атрибутами (колонками):
- «Идентификатор продажи» => «Номер документа»
- «Идентификатор продажи» => «Код валюты»
- «Номер документа» => «Код валюты»
Эти зависимости транзитивны: каждая продажа однозначно определяет свой документ-основание и расчётную валюту, однако, валюта определяется ещё и документом.
Результатом нарушения 3НФ является избыточность хранения и необходимость обновления данных в связанной таблице. Так, если вы оставите колонку «Код валюты» в таблице продаж, то при изменении валюты документа придётся также обновлять все связанные с ним строки продаж.
Демормализация в базе данных: «звезда» и «снежинка»
Как можно понять из вышеприведённых примеров, основными целями нормализации являются:
- устранение избыточности при хранении данных, приводящей к увеличению размера БД;
- исключение необходимости модификации данных в связных таблицах для минимизации времени и операций, проводящихся в одной транзакции. Или, как выражаются специалисты, уменьшить толщину транзакции, потому что толстые транзакции мешают при многопользовательской работе взаимными блокировками и увеличением времени отклика системы. Речь об этом пойдёт в отдельной главе.
Но список заявленных целей касается приложений транзакционных.
В приложениях интерактивной аналитической обработки приоритет меняется: на первый план выходит время отклика системы, в ущерб которому данные могут быть избыточны.
Зачем нужна денормализация?
Наиболее дорогостоящая с точки зрения вычислительных ресурсов операция между большими таблицами — соединение. Соответственно, если в одном запросе необходимо «провентилировать» несколько таблиц, состоящих из многих миллионов строк, то СУБД потратит достаточно много времени на такую обработку. Пользователь в это время может отойти выпить кофе. Интерактивность обработки практически исчезает и приближается к таковой для обработки пакетной. Даже хуже, в пакетном режиме пользователь с утра получает все запрошенные накануне данные и спокойно работает с ними, подготавливая новые запросы к вечеру.
Чтобы избежать ситуации тяжёлых соединений таблицы денормализуют. Но не абы как. Существуют некоторые правила, позволяющие считать денормализованные с точки зрения транзакционной обработки таблицы «нормализованными» согласно правилам построения таблиц для хранилищ данных.
Основных схем, считающихся «нормальными» в аналитической обработке, две: «снежинка» и «звезда». Названия хорошо отражают суть и следуют непосредственно из картинки связанных таблиц.
В обоих случаях центральным элементом схемы являются так называемые таблицы фактов, содержащие интересующие аналитика события, транзакции, документы и другие занятные вещи. Но если в транзакционной БД один документ «размазан» по нескольким таблицам (как минимум по двум: заголовки и строки-содержание), то в таблице фактов одному документу, точнее, каждой его строке или набору сгруппированных строк, соответствует одна запись. Сделать это можно денормализацией двух вышеупомянутых таблиц.
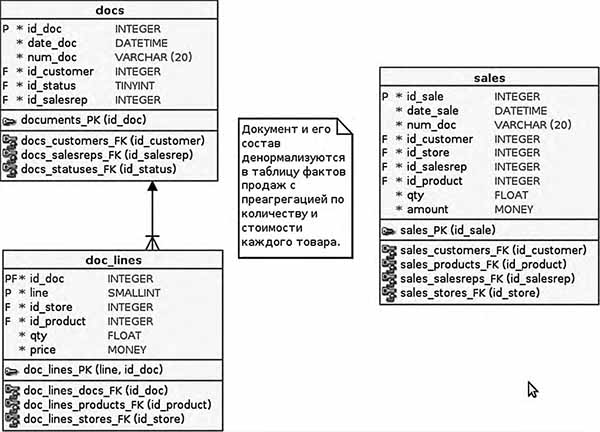
Рис. 1. Денормализация документов в таблицу фактов
Теперь можно оценить, насколько облегчится для выполнения СУБД запрос, например, следующего вида: определить объёмы продаж муки клиентам «ООО Пирожки» и «ЗАО Ватрушки» за период.
В нормализованной транзакционной БД:
В аналитической БД:
Вместо тяжёлого соединения между двумя таблицами документов и их состава с миллионами строк, СУБД достаётся прямая работа с таблицей фактов и лёгкие соединения с небольшими вспомогательными таблицами, без которых также можно обойтись, зная идентификаторы.
Вернёмся к схемам «звезда» и «снежинка». За кадром первого рисунка остались таблицы клиентов, их групп, магазинов, продавцов и, собственно, товаров. При денормализации эти таблицы, называющиеся измерениями, также соединяются с таблицей фактов. Если таблица фактов ссылается на таблицы-измерения, имеющие ссылки на другие измерения (измерения второго уровня и выше), то такая схема называется «снежинка».
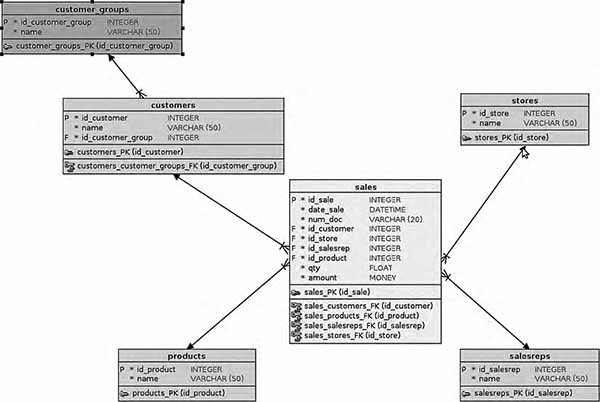
Рис. 2. Таблица фактов в схеме «снежинка»
Как можно заметить, для запросов, включающих фильтрацию по группам клиентов, приходится делать дополнительное соединение.
В таком случае денормализацию можно продолжить и опустить измерение второго уровня на первый, облегчив запросы к таблице фактов.
Схема, в которой таблица фактов ссылается только на измерения, не имеющие второго уровня, называется «звезда». Число таблиц измерений соответствует числу «лучей» в звезде.
Схема «Звезда» полностью исключает иерархию измерений и необходимость соединения соответствующих таблиц в одном запросе.
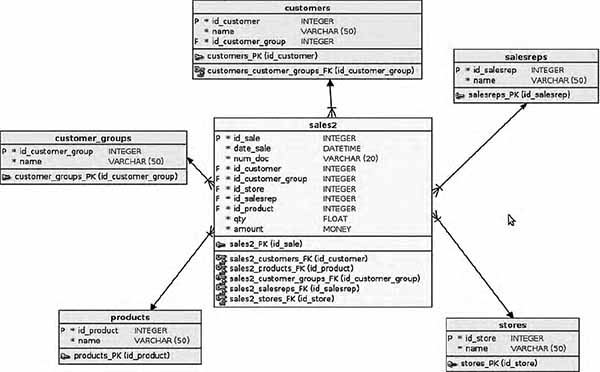
Рис. 3. Таблица фактов в схеме «звезда»
Обратной стороной денормализации всегда является избыточность, являющаяся причиной увеличения размера БД как в случае транзакционных, так и аналитических приложений. Давайте посчитаем примерную дельту на приведённом выше примере преобразования «снежинки» в «звезду».
В некоторых СУБД, например Oracle, специальные целочисленные типы на уровне определений схемы БД отсутствуют, необходимо использовать универсальный логический тип numeric(N), где N — число хранимых разрядов. Размер хранения такого числа рассчитывается по специальной формуле, приводимой в документации по физическому хранению данных, и, как правило, он превышает таковой для низкоуровневых типов вроде «16битное целое» на 1-3 байта.Положим, таблица продаж не использует компрессию данных и содержит около 500 миллионов строк, а количество групп покупателей порядка 1000. В этом случае мы можем использовать в качестве типа идентификатора id_customer_group короткое целое (shortint, smallint), занимающее 2 байта.
Будем считать, что наша СУБД поддерживает двухбайтовый целочисленный тип (например, PostgreSQL, SQL Server, Sybase и другие). Тогда добавление соответствующей колонки id_customer_group в таблицу продаж вызовет увеличение её размера как минимум на 500 000 000 * 2 = 1 000 000 000 байт
Универсальных рекомендаций по денормализации не существует , это всегда компромисс между размером БД и временем выполнения запросов. Если вы исчерпали все возможные способы оптимизации запросов и физического хранения на данной схеме БД, то следует рассмотреть возможность её дальнейшей денормализации, что, однако, не является единственным путём решения проблем производительности системы. Более распространённый способ — организация на основе хранилища данных ещё более агрегированных таблиц (витрин) и многомерных кубов, которые и будут непосредственно служить базами данных для запросов пользователей.
Создание физической модели базы данных. Учет влияния транзакций
Денормализация
Понятие о денормализации
Начиная с этого раздела мы переходим к рассмотрению методик настройки физической структуры реляционной базы данных с целью удовлетворения требования к производительности базы данных. Эти методики представляют собой набор рекомендаций и эвристических правил по изменению физической структуры базы данных , которая была получена проектировщиком базы данных в результате создания первой итерации физической модели базы данных. Ясно, что использование этих методик носит опциональный характер.
В этом разделе будут описаны различные типы денормализации и методы реализации этого процесса. Кроме того, мы рассмотрим, как использовать для поддержки денормализации триггеры и как обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования модуля. Другими словами, обычно нельзя принять решение о денормализации на основании одной только модели данных. Когда проектировщик принимает решение о денормализации , то должен господствовать здравый смысл. Обычно стараются найти в приложении базы данных критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы обычно определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Если проектировщик базы данных прописал все транзакции базы данных , то он, вероятно, сможет определить наличие таких критических процессов.
Замечание. Использовать денормализацию только для упрощения SQL-запросов при обращении к базе данных является неправильным решением. Если вы хотите упростить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Чтобы повысить производительность запроса, можно ввести индексы. Как оптимизировать запрос , будет рассмотрено в последней лекции этого курса.
Как правило, денормализация уменьшает время запроса за счет DML -операций. Денормализацию следует рассматривать как расширение нормализованной модели данных, которое повысит производительность запросов . При принятии решения о денормализации определите, что является наиболее важным для приложения – избыточность данных или высокая производительность. Если проектировщик базы данных ведет журнал проектирования (некоторый внутренний документ произвольной формы, в котором фиксируются все принятые в процессе проектирования базы данных решения), то в него необходимо занести обоснованное решение о денормализации . Помните, что кроме денормализации существуют и другие пути повышения производительности. Денормализацию таблиц можно выполнять как на уровне логической модели данных , так и на уровне физической модели .
Нисходящая денормализация
Рассмотрим принципы денормализации на уровне логической модели реляционной базы данных . Нисходящая денормализация предлагает перенос атрибута из одной (родительской) сущности в подчиненную (дочернюю) сущность. Из рисунков 10.1 и 10.2 видно, что в денормализованной логической модели мы переместили фамилию клиента из сущности Customer (Клиент) в сущность Order (Заказ). Что дает введение избыточности (перенос атрибута) в данном случае? Единственный выигрыш заключается в том, что мы исключаем операцию соединения, если захотим вместе с заказом увидеть фамилию клиента.

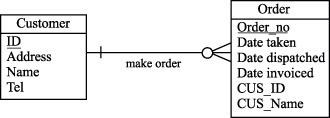
Таким образом, нисходящая денормализация – это процесс введения избыточных колонок в подчиненных таблицах с целью устранения операций соединения.
Однако устранение соединений посредством нисходящей денормализации редко оправдывает затраты на сопровождение дублирующей колонки в таблице ORDER. Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений , дающих небольшую реальную выгоду. Например, если клиент меняет фамилию, то нам приходится обновлять все заказы, чтобы отразить это изменение. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены или закрыты? Если бы не была проведена денормализация , то эти вопросы никогда бы и не возникли.
Нисходящая денормализация оправдана лишь в приложениях, где необходимо устранять операции соединения таблиц. Это имеет место в базах данных большого объема, таких как хранилища данных. При этом проблемы с каскадными обновлениями не возникает потому, что данные в хранилищах данных – архивные.
Восходящая денормализация
Восходящая денормализация предлагает перенос атрибута из подчиненной (дочерней) сущности в родительскую сущность, обычно в форме итоговых данных. На рисунках 10.3 и 10.4 показано, как это можно сделать для сущностей Order и Order Item (Позиция заказа).

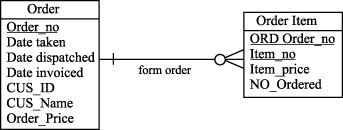
Например, если в вычисление общей суммы заказа в системы обработки заказов (суммирование колонок Item_Price в таблице Order Item ) приводит к снижению производительности, то мы можем повысить производительность этой операции, поместив сумму заказа в избыточном столбце таблицы ORDER. В нашем примере в избыточном столбце хранится сумма значений, но эти приемы применимы к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Таким образом, восходящая денормализация – это процесс введения избыточных колонок в родительских таблицах с целью устранения операций соединения с операциями агрегирования.
Чтобы представить последствия введения денормализации , рассмотрим процедуру сопровождения денормализованных таблиц Order и Order Item , которые сводятся к поддержке следующих бизнес-правил:
- Когда в таблицу Order Item добавляется новая строка, то цена заказа (колонка Order_Price ) в таблице Order увеличивается на цену новой позиции заказа (Item_Price) .
- Когда строка удаляется из таблицы Order Item , то цена заказа в таблице Order уменьшается на цену старой позиции заказа (Item_Price) .
- Когда изменяется цена в таблице Order Item , то цена заказа в таблице Order должна быть откорректирована на разницу между старой и новой ценами позиции заказа (Item_Price) .
Поддержка перечисленных выше бизнес-правил создает дополнительную нагрузку на процессы, выполняющие DML -операции в таблице Order Item . Это и есть цена, которую мы вынуждены заплатить за повышение производительности запросов.
Внутритабличная денормализация
Внутритабличная денормализация выполняется в пределах одной таблицы, т.е. это процесс введения избыточных колонок в одной таблице с целью увеличения производительности запроса строки по производному значению. Например, если строка содержит две числовых колонки, X и Y , то значение Z , равное произведению X и Y (Z = X*Y) , легко вычислить во время выполнения. Однако предположим, что есть запросы , в которых необходимо осуществить поиск по Z (например, Z принадлежит диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z , и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым – увеличение времени загрузки, вызванное необходимостью постоянно пересчитывать Z , или увеличение времени сканирования, обусловленное удлинением строк таблицы за счет хранения дополнительной колонки.
Приведем еще один часто встречающийся пример внутритабличной нормализации . Допустим, что одинаковый текст хранится в двух видах: с символами в верхнем и в нижнем регистре – для отображения и ввода данных с символами в верхнем регистре. Это бывает необходимо для обеспечения работы ускоренных запросов без учета регистра.
Примечание. Обеспечить приемлемую производительность для таблиц умеренного размера (до 10000 строк) в последнем случае можно и без внутритабличной деномализации, переработав запрос с использованием встроенной функции UPPER .
Денормализация методом “разделяй и властвуй”
Денормализация методом “разделяй и властвуй” – это процесс разбиения нормализованной таблицы на две и более таблиц и создание между ними отношения “один к одному” с целью устранения дополнительных операций ввода/вывода или по техническим причинам.
Использование этого приема носит причины технического характера. Во многих СУБД таблица не может иметь больше одного столбца типа LONG или LONG RAW . Допустим, что у вас есть таблица Films и нужно сохранить и окончательный вариант фильма ( LONG ), и вариант, который отсняли с множеством дублей ( LONG RAW ). Из-за вышеупомянутого ограничения в одной таблице это сделать нельзя, поэтому один из кодов нужно разместить в отдельной таблице. Проектировщику базы данных не остается ничего другого как разбить таблицу на две.
Иногда лучше вынести столбец LONG в отдельную таблицу, даже если вышеупомянутое ограничение не действует. Рассмотрим таблицу, строки которой содержат в начале ключевые колонки, потом неключевые колонки, а в конце – колонку типа LONG . Предположим, что в большинстве строк столбец LONG содержит данные. Если нет индексов по неключевым столбцам, то при выполнении запросов по любому из этих столбцов СУБД обычно будет осуществлять полное сканирование таблицы. При этом из-за наличия в таблице столбца LONG понадобятся дополнительные операции ввода/вывода.
Чтобы устранить эту проблему, разделите таблицу так, как показано на рис. 10.5.

Во многих СУБД таблица не может иметь более 254 столбцов, и если предложить таблицу с большим числом столбцов, то также возникнет причина для разделения такой таблицы на две. Обычно такие таблицы могут понадобиться только в следующих случаях:
- приложение полностью проектируется на базе унаследованной системы, и каждая таблица строится как точная копия файла унаследованной системы. При этом наследуется и структура, и все реляционные свойства в ней отсутствуют;
- выполняется слияние двух таблиц путем формирования в одной из них повторяющейся группы;
- речь идет о хранилище данных, в котором принято решение выполнить массовую нисходящую денормализацию . В этом случае следует создавать таблицы с максимальным для СУБД числом столбцов, так как любое другое решение, вероятно, обусловит необходимость массовых соединений “один к одному”.
Согласно мнению известного специалиста в области проектирования реляционных баз данных Д. Энсора, “Хорошей мерой степени нормализации является число столбцов на таблицу. Эмпирическое правило гласит, что очень немногие первичные ключи имеют более двадцати действительно зависимых от них атрибутов”.

