

Всегда ли нужны Docker, микросервисы и реактивное программирование?
Информационный портал по безопасности
Информационный портал по безопасности » Программирование » Всегда ли нужны Docker, микросервисы и реактивное программирование?
Всегда ли нужны Docker, микросервисы и реактивное программирование?

Автор: Денис Цыплаков, Solution Architect, DataArt
В DataArt я работаю по двум направлениям. В первом помогаю людям чинить системы, сломанные тем или иным образом и по самым разным причинам. Во втором помогаю проектировать новые системы так, чтобы они в будущем сломаны не были или, если говорить реалистичнее, чтобы сломать их было сложнее.
Если вы не делаете что-то принципиально новое, например, первый в мире интернет-поисковик или искусственный интеллект для управления запуском ядерных ракет, создать дизайн хорошей системы довольно просто. Достаточно учесть все требования, посмотреть на дизайн похожих систем и сделать примерно так же, не совершив при этом грубых ошибок. Звучит как чрезмерное упрощение вопроса, но давайте вспомним, что на дворе 2019 год, и «типовые рецепты» дизайна систем есть практически для всего. Бизнес может подкидывать сложные технические задачи — скажем, обработать миллион разнородных PDF-файлов и вынуть из них таблицы с данными о расходах — но вот архитектура систем редко отличается большой оригинальностью. Главное тут — не ошибиться с определением того, какую именно систему мы строим, и не промахнуться с выбором технологий.
В последнем пунктом регулярно возникают типичные ошибки, о некоторых из них я расскажу в статье.The Reactive Manifesto. Уже через два года после публикации манифеста он был у всех на слуху. Это действительно революционный подход к проектированию систем. Его отдельные элементы использовались десятки лет назад, но все принципы реактивного подхода вместе, в том виде, как это изложено в манифесте, позволили индустрии сделать серьезный шаг вперед к проектированию более надежных и более высокопроизводительных систем.
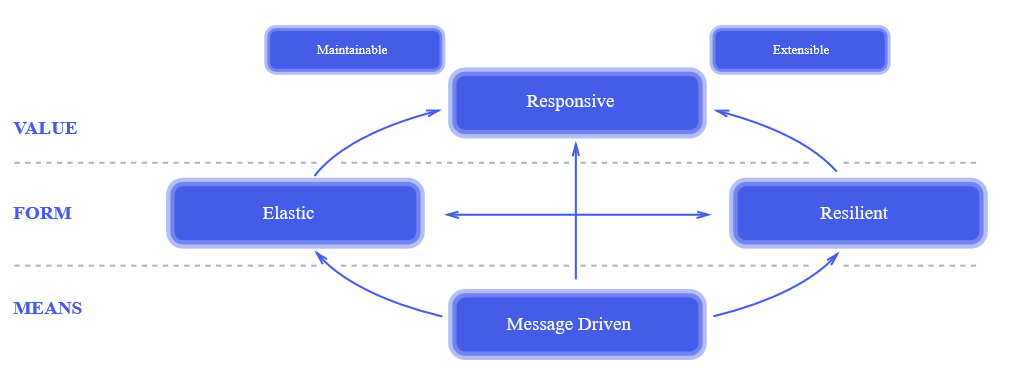
К сожалению, реактивный подход к проектированию часто путают с реактивным программированием. На вопрос, зачем в проекте использовать реактивную библиотеку, мне доводилось слышать ответ: «Это реактивный подход, ты что реактивный манифест не читал!?» Манифест я читал и подписывал, но, вот беда, реактивное программирование не имеет к реактивному подходу к проектированию систем прямого отношения, кроме того что в названиях обоих есть слово «реактивный». Можно легко сделать реактивную систему, используя на 100% традиционный набор инструментов, и создать совершенно не реактивную систему, используя новейшие наработки функционального программирования.
Реактивный подход к проектированию систем — достаточно общий принцип, применимый к очень многим системам — он определенно заслуживает отдельной статьи. Здесь же я хотел бы рассказать о применимости реактивного программирования.
В чем суть реактивного программирования? Сначала рассмотрим, как работает обычная нереактивная программа.
Нитью исполняется какой-то код, делающий какие-то вычисления. Затем наступает необходимость произвести какую-то операцию ввода-вывода, например, HTTP-запрос. Код посылает по сети пакет, и нить блокируется в ожидании ответа. Происходит переключение контекста, и на процессоре начинает исполняться другая нить. Когда по сети приходит ответ, контекст опять переключается, и первая нить продолжает исполнение, обрабатывая ответ.
Как такой же фрагмент кода будет работать в реактивном стиле? Нить исполняет вычисления, посылает HTTP-запрос и вместо того чтобы заблокироваться и при получении результата синхронно обработать его, описывает код (оставляет callback) который должен быть исполнен в качестве реакции (отсюда слово реактивный) на результат. После этого нить продолжает работу, делая какие-то другие вычисления (может быть, как раз обрабатывая результаты других HTTP-запросов) без переключения контекста.
Основное преимущество здесь — отсутствие переключения контекста. В зависимости от архитектуры системы эта операция может занимать несколько тысяч тактов. Т. е. для процессора с тактовой частотой 3 Ghz переключение контекста займет не менее микросекунды, на самом деле, за счет инвалидации кэша и т. п. скорее несколько десятков микросекунд. Говоря практически, для среднего Java-приложения, обрабатывающего много коротких HTTP-запросов — прирост производительности может составить 5-10%. Нельзя сказать, что решающе много, но, скажем, если вы арендуете 100 серверов по 50 $/мес каждый — вы сможете сэкономить $500 в месяц на хостинге. Не супермного, но хватит, чтобы несколько раз напоить команду пивом.
Итак, вперед за пивом? Давайте рассмотрим ситуацию подробно.
Программу в классическом императивном стиле значительно проще читать, понимать и как следствие отлаживать и модифицировать. В принципе, хорошо написанная реактивная программа тоже достаточно понятно выглядит, проблема в том, что написать хорошую, понятную не только автору кода здесь и сейчас, но и другому человеку через полтора года, реактивную программу намного сложнее. Но это достаточно слабый аргумент, я не сомневаюсь, что для читателей статьи писать простой и понятный реактивный код не составляет проблемы. Давайте рассмотрим другие аспекты реактивного программирования.
Далеко не все операции ввода-вывода поддерживают неблокирующие вызовы. Например, JDBC на текущий момент не поддерживает (в этом направлении идут работы см. ADA, R2DBC, но пока все это не вышло на уровень релиза). Поскольку сейчас 90 % всех приложений ходят к базам данных, использование реактивного фреймворка автоматически из достоинства превращается в недостаток. Для такой ситуации есть решение — обрабатывать HTTP-вызовы в одном пуле потоков, а обращения к базе данных в другом пуле потоков. Но при этом процесс значительно усложняется, и без острой необходимости я бы так делать не стал.
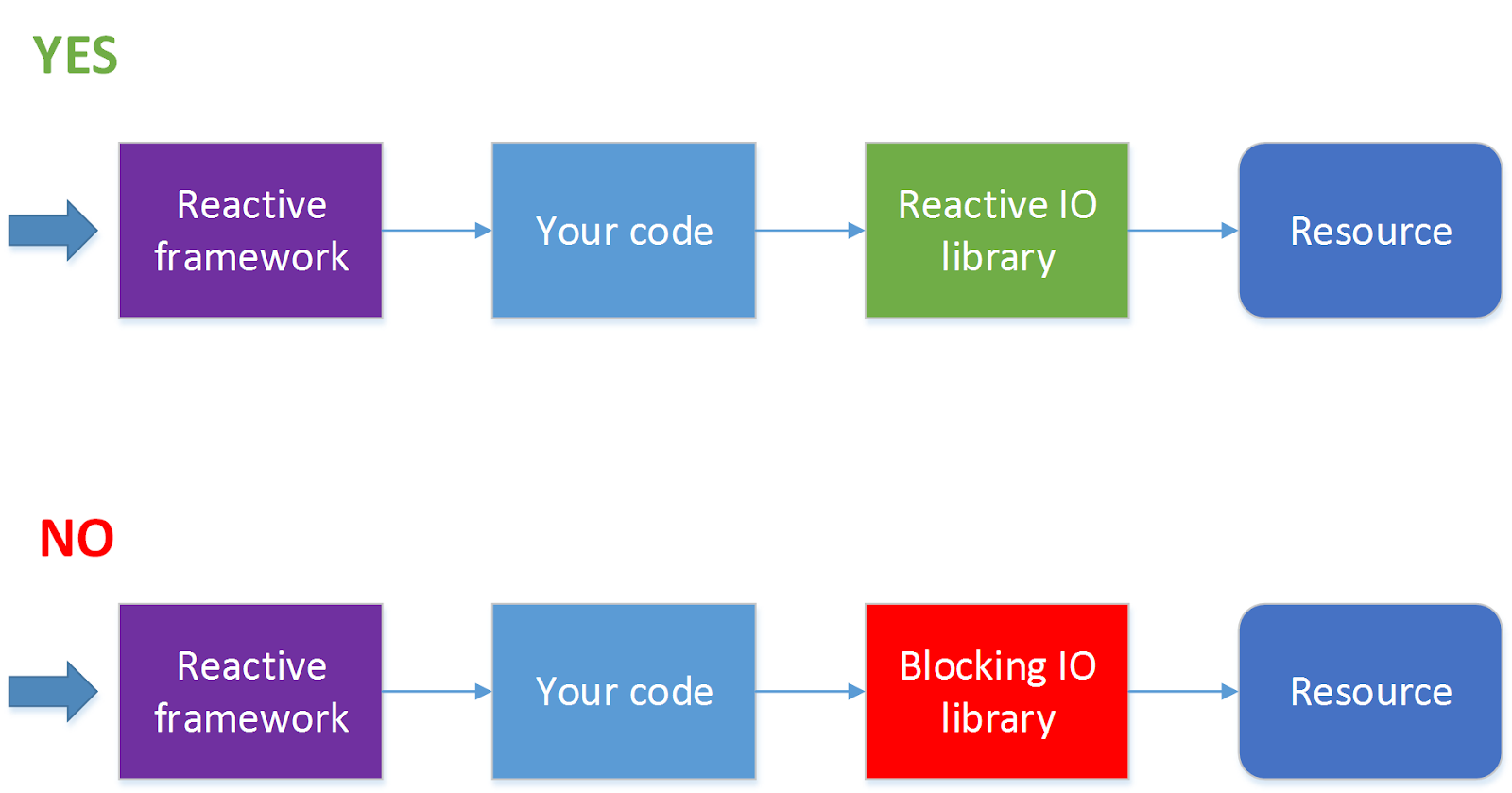
Когда стоит использовать реактивный фреймворк?
Использовать фреймворк, позволяющий производить реактивную обработку запросов, стоит, когда запросов у вас много (несколько сотен секунду и более) и при этом на обработку каждого из них тратится очень небольшое количество тактов процессора. Самый простой пример — проксирование запросов или балансировка запросов между сервисами или какая-то достаточно легковесная обработка ответов, пришедших от другого сервиса. Где под сервисом мы понимаем нечто, запрос к чему можно послать асинхронно, например, по HTTP.
Если же при обработке запросов вам надо будет блокировать нить в ожидании ответа, или обработка запросов занимает относительно много времени, например, надо конвертировать картинку из одного формата в другой, писать программу в реактивном стиле, возможно, не стоит.
Также не стоит без необходимости писать в реактивном стиле сложные многошаговые алгоритмы обработки данных. Например, задачу «найти в каталоге и всех его подкаталогах файлы с определенными свойствами, сконвертировать их содержимое и переслать другому сервису» можно реализовать в виде набора асинхронных вызовов, но, в зависимости от деталей задачи, такая реализация может выглядеть совершенно непрозрачно и при этом не давать заметных преимуществ перед классическим последовательным алгоритмом. Скажем, если эта операция должна запускаться раз в сутки, и нет большой разницы, будет она исполняться 10 или 11 минут, возможно, стоит выбрать не самую что ни на есть лучшую, а более простую реализацию.
Заключение
В заключение хочется сказать, что любая технология всегда предназначена для решения конкретных задач. И если при проектировании системы в обозримой перспективе эти задачи перед вами не стоят, скорее всего, эта технология вам здесь и сейчас не нужна, какой бы прекрасной она при этом ни была.
Архитектура информационных систем
 Айтишники довольно сильно разобщены. Разработчики информационных систем, системные администраторы, эксперты по большим и маленьким данным, специалисты, отвечающие за ИТ-процессы и пр. глубоко копают, но каждый в своем направлении. И в каждом из этих направлений регулярно происходят те или иные революционные изменения. Например, в заметке об Open Digital API я немного затронул тему микросервисов. Вроде бы хорошая идея. Но поинтересуйтесь у разработчика, в чем заключается конкретная польза такого подхода, и в ответ вы услышите набор общих фраз. Или другой пример – PaaS. На вопрос, чем частное облако отличается от виртуализации, следует примерно такой ответ: в частном облаке вы выделяете себе виртуальную машину самостоятельно, без участия администратора, а простая виртуализация – это когда вас пару месяцев мурыжат заявками и согласованиями (подробнее см. Призрак Digital на пороге вашего офиса). В принципе, данный ответ верен. Но зачем пользователям самостоятельно создавать себе виртуальные машины? Ответ понятен если вы хостинг-провайдер, но зачем это нужно в обычной корпоративной среде? Для того, чтоб найти ответы надо собрать все вместе и PaaS и microservices и жизненные циклы разработки и эксплуатации программного обеспечения. По отдельности оно не работает
Айтишники довольно сильно разобщены. Разработчики информационных систем, системные администраторы, эксперты по большим и маленьким данным, специалисты, отвечающие за ИТ-процессы и пр. глубоко копают, но каждый в своем направлении. И в каждом из этих направлений регулярно происходят те или иные революционные изменения. Например, в заметке об Open Digital API я немного затронул тему микросервисов. Вроде бы хорошая идея. Но поинтересуйтесь у разработчика, в чем заключается конкретная польза такого подхода, и в ответ вы услышите набор общих фраз. Или другой пример – PaaS. На вопрос, чем частное облако отличается от виртуализации, следует примерно такой ответ: в частном облаке вы выделяете себе виртуальную машину самостоятельно, без участия администратора, а простая виртуализация – это когда вас пару месяцев мурыжат заявками и согласованиями (подробнее см. Призрак Digital на пороге вашего офиса). В принципе, данный ответ верен. Но зачем пользователям самостоятельно создавать себе виртуальные машины? Ответ понятен если вы хостинг-провайдер, но зачем это нужно в обычной корпоративной среде? Для того, чтоб найти ответы надо собрать все вместе и PaaS и microservices и жизненные циклы разработки и эксплуатации программного обеспечения. По отдельности оно не работает
На днях мне пришлось столкнуться с проектом Docker. Вроде бы ничего необычного, ну оформляем код в контейнерах, ну развертываем их чуть более эффективно, чем раньше. Подробнее о решении написано здесь Microservices, Docker and Containers, an Overview, но вопрос тот же самый – зачем это все. У проекта красивая метафора (см. рисунок), но дело конечно не в ней. Даже не в этом конкретном проекте. Просто метафора Docker-а позволяет легко понять, как меняется жизненный цикл разработки и развертывания ПО.

Еще задолго до появления Rational Unified Process(и уж тем более задолго до появления гибких методологий) самым сложным релизом системы считался первый. Не помню точно кому принадлежит крылатая фраза о том, что невозможно запустить сложную систему. Такую систему можно «вырастить» из простой работающей системы. Все разработчики в это верят. Надо запустить что-нибудь, показать заказчику и затем итерационно и инкрементально наращивать функционал. Мол так снижаются риски и пр. Но давайте от книжек и конференций вернемся в реальность. У релиза с номером 1 есть некоторые преимущества, причем более существенные, чем пока еще не очень рассерженный заказчик. Во-первых, у вас нет исторических данных – операций, пользователей, кривых настроек и пр. Во-вторых, не надо заботиться об обратной совместимости. (Я не беру в расчет проект, задача которого поменять старую систему на новую, сохранив имеющийся функционал. Эта ситуация находится за гранью добра и зла). И, пожалуй, самое главное, вы можете развертываться на продуктиве. Ну есть(была) в организациях такая традиция. Для нового проекта было принято покупать новые сервера. Порой эти новенькие блестящие, пахнущие свежей краской, железячки сначала отдают программистам, чтоб они использовали их в качестве среды разработки. Те на них все поставят, настроят, отладят и потом позовут тестировщиков. Ну, на чем же еще производить нагрузочное тестирование, как не на серверах, которые пойдут в продуктив. Не проект, а идиллия. Но все хорошее рано или поздно заканчивается. Сначала придут безопасники и все на этих серверах обезопасят. Затем сервера с развернутой системой отдадут администраторам и корабль двинется в открытое море. Наутро все участники процесса вдруг резко сообразят, что у них нет ни тестовой ни разработческой среды. Администраторы, естественно, никого на продуктив не пустят, а разрыв в отношениях между Dev-ами и Ops-ами начнет стремительно нарастать. Еще вчера до корабля можно было дотянуться рукой, а сегодня он превратился в крошечную точку на горизонте. В общем дальше начинается хорошо знакомый всем корпоративным айтишникам процесс создания и синхронизации сред. Почему система прошедшая тестирование не работает на продуктиве? Ответ: среды не совпадают. Можно ли получить копию реальных данных с работающей системы? Нет, нельзя! Это секретная информация. А хотя бы настройки? Тем более нельзя. Одним словом разработка следующего релиза представляет собой стрельбу по невидимой мишени с завязанными глазами. Есть счастливое исключение. Это релиз типа appendix. Иногда вас просят разработать отдельный компонент, который слабо связан с другими модулями системы. Более того, иногда под такой компонент выделяют отдельное железо. Но это счастливое исключение.
Вспоминаем о контейнерах. В PaaS парадигме код не переезжает из одной среды в следующую. Релиз начинается с того, что вы получаете контейнер, который впоследствии станет кусочком продуктива. В этом контейнере уже установлено прикладное ПО: СУБД, фреймвоки, конфигурации, модули программной платформы и прочие нужные вещи(картриджи). Именно вместе с этими версиями 3d party software контейнер поедет в тестирование, а затем и в эксплуатацию. С теми самыми, которые уже сейчас у вас под рукой. Администратор не будет читать по бумажке руководство по установке и настройке программного обеспечения, держа его в одной руке и нажимая другой рукой кнопки на клавиатуре. Он вообще ничего не будет делать. Ну, может, посмотрит лениво на сообщение о завершении процесса изменения статуса вашего контейнера, да и то вряд ли. Предыдущий релиз вашего компонента никто не будет выключать. Он останется в продуктиве и будет работать еще некоторое время, пока с него полностью не переключат нагрузку на новый модуль. Потенциально в продуктиве могут работать несколько версий одного и того же модуля.
Возможно ли такое в реальной жизни? У всех по-разному. Рассмотрим несколько потенциальных возражений:
- У нас продуктив – это большая дорогая железка, а среда разработки представляет собой простенький стенд, собранный на нескольких писюках. Вам не повезло. В реальной жизни и продуктивная и тестовая и разработческая среда представляют собой виртуальные машины. Когда контейнер «переезжает из одной среды в другую ему просто увеличивают объем виртуальных ресурсов.
- Нельзя заменить небольшой фрагмент системы, не затронув другие модули. Это зависит от архитектуры. Еще в прошлом веке разработчики любили писать модули, которые читают записи из БД, удовлетворяющие некоторому условию, что-нибудь с ними делают и обновляют статус в базе. Потом их научили очередям сообщений, снабдили брокерами, раскладывающими сообщения по разным очередям и т.д. Теперь их подсадили на микросервисы – виртуальные машины, реализующие один набор API и использующие другой. Внутри такой машины может быть что угодно: свой фреймворк, свои хранилища, данные и пр.
- А как же данные? Зависит от того, собираетесь ли вы их читать или писать. Здесь было много разговоров о CQRS и Event Sourcing. Это о том, что не надо в одном методе одновременно читать и изменять данные. Если вам надо читать данные, то потенциально эта функция доступна и разработческой и в тестовой среде. Для обеспечения конфиденциальности, данные могут маскироваться на лету. В крайнем случае, можно создать отдельный контейнер с витриной данных и отдать его вам для разработки и тестирования. Если данные надо писать, то делать это лучше асинхронно, через очередь сообщений. В общем, отправляете сообщения в очередь и отправляете. Все эти паттерны подробно обсуждались еще во времена event-driven architecture. Есть еще пул добрых советов по разделению данных на транзакционные, референсные и мастер данные, использованию Data Integration Hub и т.д.
- В наших процедурах предусмотрен другой порядок развертывания. Ну, конечно. Мне всегда было интересно, как в ходе спринта пользователю доставляется работающий функционал. В Scrum ничего об этом не сказано. Выбираем из бэклога пользовательские истории, разрабатываем софт, затем случается магия и в завершении спринта пользователь уже работает с новым функционалом. А если магия не случилась, то возвращаемся к итерационной или водопадной модели, так?
Конечно, не все так просто. Для старых систем такой жизненный цикл не применим. Да и в новых системах будет огромное количество архитектурных вопросов и компромиссов. Но, как и в истории с контейнерными перевозками (см. мелкий шрифт на предыдущем рисунке), мир уже никогда больше не будет таким как прежде.

Update: Планирую сделать десяток слайдов на эту тему. Если тема показалась интересной, то буду рад приглашению на вебинар или очное выступление.
7 случаев, в которых не стоит использовать Docker
Перевод статьи «7 Cases When You Should Not Use Docker».

Docker это потрясающая вещь, но это решение не на все случаи жизни.
У Docker много достоинств. Этот легковесный, портируемый и самодостаточный инструмент контейнеризации. Он отлично подходит для бизнеса любого размера.
Когда вы работаете над кодом в маленькой команде, благодаря Docker вы избавлены от проблемы «а на моей машине это работает». Но корпорации тоже могут использовать Docker для создания конвейеров производства программ по методике Agile, чтобы выпускать новый функционал быстрее и безопаснее.
Благодаря своей встроенной системе контейнеризации Docker является отличным инструментом для облачных вычислений. Docker Swarm, в свою очередь, развивает кластеризацию и децентрализованный дизайн.
Звучит слишком хорошо, чтобы быть правдой, верно? Ну, все-таки есть несколько случаев, когда использовать Docker не стоит. Мы рассмотрим семь из них.
1. Не используйте Docker, если вам нужно увеличить скорость работы вашего приложения
Контейнеры Docker занимают меньше места и требуют меньше ресурсов, чем виртуальная машина с сервером и базой данных. В то же время Docker будет использовать столько системных ресурсов, сколько ему позволит планировщик ядра хоста. В любом случае, не стоит рассчитывать на то, что Docker ускорит работу вашего приложения.
Больше того, Docker даже может ее замедлить. Работая с ним, следует устанавливать для контейнеров лимиты использования памяти, CPU или блока ввода-вывода. В противном случае, если ядро обнаружит, что память машины-хоста слишком загружена для выполнения важных системных функций, оно может начать убивать важные процессы. А если будут убиты не те процессы (включая сам Docker), система станет нестабильной.
К сожалению, улучшения Docker, касающиеся памяти — приоритет out-of-memory демона Docker — не решают эту проблему. Напротив, добавление еще одного уровня между приложением и операционной системой также может привести к снижению скорости. Впрочем, это снижение будет незначительным. Контейнеры Docker не полностью изолированы и не содержат полной операционной системы, как и любая виртуальная машина.
2. Не используйте Docker, если ваш приоритет — безопасность
Самое большое преимущество Docker по части безопасности состоит в том, что он разбивает приложение на меньшие части. Если безопасность одной части будет скомпрометирована, на остальные это не повлияет.
Но несмотря на то, что изолированность процессов в контейнерах повышает безопасность, все эти контейнеры имеют доступ к одной операционной системе хоста. Есть риск запустить контейнеры Docker с неполной изолированностью. Какой-нибудь вредоносный код может получить доступ к памяти вашего компьютера.
Запуск множества контейнеров в одной среде это довольно популярная практика. И таким образом, если вы не ограничиваете ресурсы, доступные контейнеру, вы делаете ваше приложение уязвимым для атак типа Resource Abuse («злоупотребление ресурсами»). Для максимальной эффективности и изолированности каждый контейнер должен быть предназначен для решения какой-то одной конкретной задачи.
Еще одна проблема дефолтной конфигурации Docker — пользователи не имеют пространства имен. Пространство имен позволяет программным ресурсам использовать другие ресурсы, только если они принадлежат к определенному пространству имен.
Запуск приложений с помощью Docker подразумевает запуск демона Docker с привилегиями root. Любые процессы, исходящие из контейнера Docker, будут иметь те же привилегии на хосте, что и в контейнере. Запуск ваших процессов внутри контейнеров от имени непривилегированного пользователя не может гарантировать безопасность. Имеют значение возможности, которые вы добавляете или удаляете. Чтобы снизить риск пробоя контейнера Docker, не следует загружать готовые к использованию контейнеры из ненадежных источников.
![]()
![]()
3. Не используйте Docker, если вы создаете десктопное приложение с графическим пользовательским интерфейсом
Docker не подходит для приложений, предполагающих наличие полнофункционального UI. Он главным образом нацелен на изолированные контейнеры с консольными приложениями. Программы с графическим интерфейсом не в приоритете, их поддержка может варьироваться в зависимости от каждого конкретного случая и приложения. В Windows в качестве операционной системы контейнеров используются Nano Server или Core Server — это не позволяет пользователям запускать GUI-интерфейс или Docker RDP сервер в контейнере Docker.
Тем не менее, вы можете запускать графические приложения, разработанные на Python и при помощи QT-фреймворка в контейнере Linux. Также можно использовать перенаправление X11, но это не совсем изящное решение.
4. Не используйте Docker, если вам нужно упростить разработку и отладку
Docker был создан разработчиками и для разработчиков. Он обеспечивает стабильность среды: контейнер будет работать в стейджинге, продакшене или в любой другой среде точно так же, как на компьютере разработчика. Это устраняет проблему различных версий программ в разных средах.
С Docker вы можете легко добавить новую зависимость в ваше приложение. Причем никому из вашей команды не придется повторять эти манипуляции на своем компьютере. В контейнере все будет в рабочем состоянии и в таком виде будет распределено по всей команде.
В то же время, чтобы вести разработку приложения в Docker, следует дополнительно продумать и настроить рабочие процессы. Кроме того, для дебаггинга в Docker нужно настроить вывод логов и порты для отладки. Может также понадобиться назначить порты для ваших приложений и сервисов в контейнерах.
В общем, если у вас сложная и трудоемкая процедура деплоймента, Docker вам существенно поможет. А если у вас простое приложение, он только все усложнит.
5. Не используйте Docker, если вам нужно использовать другую операционную систему или другое ядро
В случае с виртуальными машинами гипервизор может абстрагировать устройство целиком. При помощи Microsoft Azure можно запустить Windows Server и Linux Server одновременно. А вот для образа Docker необходима та же операционная система, для которой он был создан.
Существует обширная база образов контейнеров Docker — Docker Hub. Но если какой-то отдельно взятый образ был создан на Linux Ubuntu, его можно будет запустить только на точно такой же Ubuntu.
Если приложение разрабатывается на Windows, но продакшен запускается на Linux, использование Docker в этом случае будет неэффективным. Порой, если у вас несколько статичных приложений, проще поднять сервер.

6. Не используйте Docker, если вам нужно хранить много ценных данных
Все файлы Docker создаются внутри контейнера и хранятся на слое, доступном для записи. Если каким-то процессам нужны будут данные из контейнера, могут возникнуть трудности с их получением. Кроме того, слой контейнера, доступный для записи, связан с хостом, где запущен контейнер. Если у вас возникнет необходимость перенести данные куда-то еще, это нелегко будет сделать. Более того: при прекращении работы контейнера будут навсегда потеряны все данные, хранящиеся внутри него.
Нужно наперед продумывать способы сохранения данных где-то еще. Для обеспечения безопасности данных в Docker используется дополнительный инструмент — Docker Data Volumes. Но это решение тоже довольно топорное и нуждается в улучшении.
7. Не используйте Docker, если ищете технологию, управлять которой будет проще всего
Docker был представлен широкой публике в 2012 году, но все еще является новой технологией. Вам как разработчику может потребоваться регулярно обновлять версии Docker. К сожалению, обратная совместимость при этом не гарантирована, да и развитие документации отстает от развития самой технологии. Разработчику придется во многом разбираться самостоятельно.
Опции мониторинга, предлагаемые Docker, довольно скудны. Вы можете получить какие-то сведения типа самой простой статистики, но если вам нужен более продвинутый функционал мониторинга, Docker-у нечего вам предложить.
В случае с крупными и сложными приложениями имплементация Docker обходится дорого. Создание и поддержка коммуникации между многочисленными контейнерами на многочисленных серверах потребует много времени и сил. Есть, конечно, инструмент, облегчающий работу с многоконтейнерными приложениями Docker, — Docker Compose. Он определяет сервисы, сети и разделы в одном YAML-файле.
Экосистема Docker не отличается цельностью: не все продукты для поддержки контейнеров хорошо работают друг с другом. За всеми продуктами стоят разные компании и сообщества. Конкуренция между ними приводит к несовместимости продуктов.
Заключение
Несмотря на некоторые оговорки, Docker это отличный инструмент для запуска приложений в изолированных контейнерах и управления ими.
Установка приложения проста и осуществляется при помощи всего одной команды — . Также Docker предоставляет чистую и оригинальную среду изоляции для каждого теста, что делает его важным и полезным инструментом для автоматического тестирования.
Благодаря функционалу Docker вы получаете существенные преимущества по части безопасности и управления зависимостями. А дополнение этого функционала такими полезными инструментами как Docker Hub, Docker Swarm и Docker Compose делает Docker популярным и дружественным к пользователю решением.
Но несмотря на все преимущества, которые дает Docker, не стоит использовать его для контейнеризации буквально всех приложений, которые вы разрабатываете. Это не волшебная палочка.
Также не стоит забывать, что Docker — не единственный подобный инструмент на рынке. Есть и альтернативы: rkt (произносится как «рокет»), Linux Containers, OpenVZ. Все они имеют свои достоинства и недостатки и все они похожи на Docker. Особая популярность последнего связана только с решением бизнеса использовать именно его.
Прежде чем решиться использовать или не использовать Docker, изучите требования проекта и обсудите этот вопрос с коллегами.
У этой технологии определенно есть будущее, независимо от того, нравится она вам или нет. Есть разработчики и компании, просто ненавидящие Docker и пытающиеся удалить его из всех своих проектов. В то же время, есть специалисты, считающие Docker панацеей от всех бед и заключающие в контейнеры все, что только можно. Вероятно, не стоит присоединяться к какому-то из этих двух лагерей. Оставайтесь объективными и принимайте решение в зависимости от каждой отдельной ситуации.

