

Java и Project Reactor. Эпизод 2
Java и Project Reactor. Эпизод 2

Я отрекаюсь от магии
Для дальнейшего углубления в Reactor не будет лишним описать некоторые принципы его работы. Что же тщательно скрывается от нас за внешним слоем из Flux и Mono?
Flux и Mono реализуют интерфейс Publisher.
Официальная документация предлагает сравнивать Reactor с конвейером. Publisher выдаёт какие-то данные (материалы). Данные идут по цепочке из операторов (конвейерной ленте), обрабатываются, в конце получается готовый продукт, который передаётся в нужный Consumer/Subscriber и употребляется уже там.
Как работают операторы Reactor? Рецепт усреднённый, потому что вариаций масса. Попытаемся дать грубое описание.
У каждого оператора есть какая-то тактика реализация в виде объекта. Вызов оператора у Flux/Mono возвращает объект, реализующий этот оператор. Например, вызов flatMap() вернёт объект типа FluxFlatMap (наследник Flux).
Т.е. оператор — это Publisher, который, помимо какой-то своей логики, содержит ссылку на исходный (source) Publisher, к которому применяется. Вызовы операторов создают цепочку из Publisher.
При вызове subscribe() создаётся исходный Subscriber, он передаётся назад по нашей цепочке из паблишеров, каждый Publisher может завернуть Subscriber в другой Subscriber, таким образом создавая ещё одну цепочку, которая и передаётся в исходный Publisher для выполнения.
Логично, что всё это несёт какой-то оверхед, поэтому рекомендуется воздержаться от написания обычного (синхронного) кода через Flux или Mono.
Schedulers | Планировщики
Reactor не заботит модель исполнения вашей программы, но он любезно предоставляет необходимый для управления исполнением инструментарий. Разработчик самурай волен самостоятельно выбирать свою судьбу модель исполнения.
Модель исполнения и её детали определяются имплементацией интерфейса Scheduler (т.е. планировщика). Есть статические методы для ряда случаев жизни, позволяющие указать контекст выполнения:
- Schedulers.immediate(). Выполнение будет происходить в текущем потоке;
- Schedulers.single(). Выполнение в выделенном потоке. Осторожно! Он и в самом деле single, обращение не создаст новый scheduler/поток, а вернёт кешированное значение. Для создания выделенного потока/scheduler на каждый вызов используйте Schedulers.newSingle();
- Schedulers.elastic(). Уже упоминался в прошлой статье. Выполнение задач списывает на workers (работяг, «воркеров»), которых сам же и создаёт. В случае idle (бездействия) worker прибивается. В качестве воркера выступает ExecutorService. Используется для блокирующих задач, например I/O. По умолчанию — unbounded, если нужно ограничение на количество воркеров — используйте Schedulers.newElastic();
- Schedulers.parallel(). N воркеров, оптимизированных для параллельной работы. По умолчанию N = количеству доступных ядер, т.е. Runtime.getRuntime().availableProcessors(). Осторожно! Внутри Docker этот метод может нагло вам врать.
Стоит отметить, что коробочные Schedulers.single() и Schedulers.parallel() выбрасывают IllegalStateException при попытке запустить в них блокирующий оператор: block(), blockLast(), toIterable(), toStream(). Такое нововведение появилось в релизе 3.1.6.
Если всё-таки хотите заниматься подобными извращениями — используйте Shchedulers.newSingle() и Schedulers.newParallel(). Но лучшей практикой для блокирующих операторов считается использование Schedulers.elastic() или Schedulers.newElastic().
Экземпляры Scheduler так же можно инициализировать из ExecutorService с помощью Schedulers.fromExecutorService(). Из Executor тоже можно, но не рекомендуется.
Некоторые операторы из Flux и Mono запускаются сразу на конкретном Scheduler (но можно передать и свой). К примеру, уже знакомый Flux.interval() по умолчанию запускается на Schedulers.parallel().
Контекст исполнения
Как же сменить контекст исполнения? Нужно прибегнуть к одному из уже знакомых нам операторов:
Они оба принимают Scheduler в качестве аргумента и позволяют изменить контекст выполнения на указанный Scheduler.
Но почему их два и в чём же разница?
В случае с publishOn этот оператор применяется так же, как и любой другой, посреди цепочки вызовов. Все последующие Subscriber будут выполняться в контексте указанного Scheduler.
В случае с subscribeOn оператор «глобальный», срабатывает сразу на всю цепочку Subscriber. После вызова subscribe() контекстом выполнения будет указанный Scheduler. Далее контекст может изменяться с помощью оператора publishOn. Последующие вызовы subscribeOn игнорируются.
выведет следующий результат:
Обработка ошибок
В Reactor исключения воспринимаются как terminal event (терминальное событие).
Если где-то произошло исключение, значит, что-то пошло не так, наш конвейер останавливается, а ошибка прокидывается до финального Subscriber и его метода onError.
Почему так? Reactor не знает о серьёзности возникшего исключения и понятия не имеет, что с ним делать. Подобные ситуации должны как-то обрабатываться на уровне приложения. Для этого у Subscriber есть прекрасный метод onError(). Reactor вынуждает нас его переопределять и как-то реагировать на исключение, в противном случае мы будем получать UnsupportedOperationExceptionпри ошибках.
Философия try/catch
Что обычно делается внутри catch-блока в Java? Ну, не считая всеми любимых пустых catch-блоков.
- Static Fallback Value. Вернуть какое-то статическое значение по умолчанию:
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) - Fallback Method. Вызов альтернативного метода в случае ошибки:
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) - Dynamic Fallback Value. Вернуть какое-то динамическое значение в зависимости от исключения:
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) < if (e instanceof TimeoutException) < return loadValueFromCache(); >return DEFAULT_VALUE; > - Catch and Rethrow. Обернуть в какое-то доменное исключение и пробросить исключение дальше:
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) - Log or React on the Side. Залогировать ошибку и пробросить исключение дальше:
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) - Using Resources and the Finally Block. Освобождение ресурсов в finally-блоке или с помощью try-with-resources.
try < return fromRemoteAndUnstableSource(); >catch(Throwable e) < //do nothing >finally
Приятная новость: всё это есть в Reactor в виде эквивалентных операторов.
Менее приятная новость: в случае ошибки ваша прекрасная последовательность данных всё равно завершится (terminal event), несмотря на оператора обработки ошибок.
Подобные операторы используются скорее для создания новой, резервной (fallback) последовательности на замену завершившейся.
Можно сравнить это с похожим блоком try / catch:
Обратите внимание: for прерывается!
Ещё пример завершения последовательности в случае ошибки:
На экране получим:
Реализация try/catch
Static Fallback Value
Используя оператор onErrorReturn:
Можно добавить предикат, чтобы оператор выполнялся не для всех исключений:
Fallback Method
Используя оператор onErrorResume,
можно добавить предикат, чтобы оператор выполнялся не для всех исключений:
Dynamic Fallback Value
Всё тот же onErrorResume:
Catch and Rethrow
Можно сделать двумя способами. Первый — с оператором onErrorResume:
И более лаконично — с помощью onErrorMap:
Log or React on the Side
Добавить какой-то side effect (метрики, логирование) можно с помощью оператора doOnError
Using Resources and the Finally Block
Итак, как же получить аналог try-with-resources или блок finally? На выручку нам приходит оператор Flux.using().
Для начала нужно ознакомиться с интерфейсом Disposable. Он заставляет нас реализовать метод dispose(). Вызов этого метода должен отменять или завершать какую-то задачу или последовательность. Вызовы метода должны быть идемпотентными. Использованные ресурсы должны быть освобождены.
Повторение | Retrying
При повторе (retry) наблюдается похожее поведение, оригинальная последовательность завершается (terminate event), мы повторно подписываемся (re-subscribing) на Flux.
Разберём на примере. Код
Более сложная логика повторов доступна с использованием оператора retryWhen().
Заключение
Надеюсь, этой небольшой заметке удалось пролить свет на некоторые особенности работы Reactor.
- контекстом выполнения можно манипулировать с помощью операторов publishOn, subscribeOn и Schedulers;
- для обработки исключительных ситуаций есть множество операторов
на все случаи жизни; - посылание terminate signal приводит к завершению оригинальной «последовательности»;
- для освобождения ресурсов используется интерфейс Dispose.
Java и Project Reactor. Эпизод 2

Привет! Удивительно, но первая часть статьи даже кому-то понравилась.
Отдельное спасибо за ваши отзывы и комментарии. У меня для вас плохая хорошая новость: нам ещё есть о чём поговорить! А если точнее, то о некоторых деталях работы Reactor.
Я отрекаюсь от магии
Для дальнейшего углубления в Reactor не будет лишним описать некоторые принципы его работы. Что же тщательно скрывается от нас за внешним слоем из Flux и Mono?
Flux и Mono реализуют интерфейс Publisher.
Официальная документация предлагает сравнивать Reactor с конвейером. Publisher выдаёт какие-то данные (материалы). Данные идут по цепочке из операторов (конвейерной ленте), обрабатываются, в конце получается готовый продукт, который передаётся в нужный Consumer/Subscriber и употребляется уже там.
Как работают операторы Reactor? Рецепт усреднённый, потому что вариаций масса. Попытаемся дать грубое описание.
У каждого оператора есть какая-то тактика реализация в виде объекта. Вызов оператора у Flux/Mono возвращает объект, реализующий этот оператор. Например, вызов flatMap() вернёт объект типа FluxFlatMap (наследник Flux).
Т.е. оператор — это Publisher, который, помимо какой-то своей логики, содержит ссылку на исходный (source) Publisher, к которому применяется. Вызовы операторов создают цепочку из Publisher.
При вызове subscribe() создаётся исходный Subscriber, он передаётся назад по нашей цепочке из паблишеров, каждый Publisher может завернуть Subscriber в другой Subscriber, таким образом создавая ещё одну цепочку, которая и передаётся в исходный Publisher для выполнения.
Логично, что всё это несёт какой-то оверхед, поэтому рекомендуется воздержаться от написания обычного (синхронного) кода через Flux или Mono.
Schedulers | Планировщики
Reactor не заботит модель исполнения вашей программы, но он любезно предоставляет необходимый для управления исполнением инструментарий. Разработчик самурай волен самостоятельно выбирать свою судьбу модель исполнения.
Модель исполнения и её детали определяются имплементацией интерфейса Scheduler (т.е. планировщика). Есть статические методы для ряда случаев жизни, позволяющие указать контекст выполнения:
- Schedulers.immediate(). Выполнение будет происходить в текущем потоке;
- Schedulers.single(). Выполнение в выделенном потоке. Осторожно! Он и в самом деле single, обращение не создаст новый scheduler/поток, а вернёт кешированное значение. Для создания выделенного потока/scheduler на каждый вызов используйте Schedulers.newSingle();
- Schedulers.elastic(). Уже упоминался в прошлой статье. Выполнение задач списывает на workers (работяг, «воркеров»), которых сам же и создаёт. В случае idle (бездействия) worker прибивается. В качестве воркера выступает ExecutorService. Используется для блокирующих задач, например I/O. По умолчанию — unbounded, если нужно ограничение на количество воркеров — используйте Schedulers.newElastic();
- Schedulers.parallel(). N воркеров, оптимизированных для параллельной работы. По умолчанию N = количеству доступных ядер, т.е. Runtime.getRuntime().availableProcessors(). Осторожно!Внутри Docker этот метод может нагло вам врать.
Стоит отметить, что коробочные Schedulers.single() и Schedulers.parallel() выбрасывают IllegalStateException, при попытке запустить в них блокирующий оператор: block(), blockLast(), toIterable(), toStream(). Такое нововведение появилось в релизе 3.1.6.
Если всё-таки хотите заниматься подобными извращениями — используйте Shchedulers.newSingle() и Schedulers.newParallel(). Но лучшей практикой для блокирующих операторов считается использование Schedulers.elastic() или Schedulers.newElastic().
Экземпляры Scheduler так же можно инициализировать из ExecutorService с помощью Schedulers.fromExecutorService(). Из Executor тоже можно, но не рекомендуется.
Некоторые операторы из Flux и Mono запускаются сразу на конкретном Scheduler (но можно передать и свой). К примеру, уже знакомый Flux.interval(), по умолчанию запускается на Schedulers.parallel().
Контекст исполнения
Как же сменить контекст исполнения? Нужно прибегнуть к одному из уже знакомых нам операторов:
- publishOn();
- subscribeOn().
Они оба принимают Scheduler в качестве аргумента и позволяют изменить контекст выполнения на указанный Scheduler.
Но почему их два и в чём же разница?
В случае с publishOn этот оператор применяется так же, как и любой другой, посреди цепочки вызовов. Все последующие Subscriber будут выполняться в контексте указанного Scheduler.
В случае с subscribeOn оператор «глобальный», срабатывает сразу на всю цепочку Subscriber. После вызова subscribe() контекстом выполнения будет указанный Scheduler. Далее контекст может изменяться с помощью оператора publishOn. Последующие вызовы subscribeOn игнорируются.
выведет следующий результат:
Обработка ошибок
В Reactor исключения воспринимаются как terminal event (терминальное событие).
Если где-то произошло исключение, значит, что-то пошло не так, наш конвейер останавливается, а ошибка прокидывается до финального Subscriber и его метода onError.
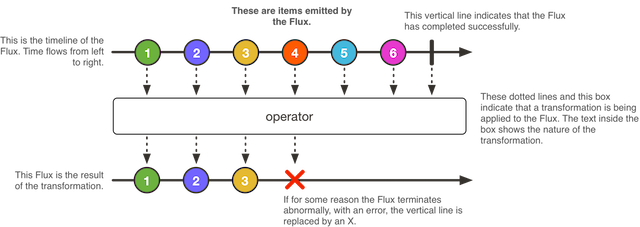
Почему так? Reactor не знает о серьёзности возникшего исключения и понятия не имеет, что с ним делать. Подобные ситуации должны как-то обрабатываться на уровне приложения. Для этого у Subscriber есть прекрасный метод onError(). Reactor вынуждает нас его переопределять и как-то реагировать на исключение, в противном случае мы будем получать UnsupportedOperationException при ошибках.
Если быть честным, то выкидывает он наследника UnsupportedOperationException — ErrorCallbackNotImplemented. Чтобы понять, что это действительно он, существует вспомогательный статический метод Errors.errorCallbackNotImplemented(Throwable t).
Философия try/catch
Что обычно делается внутри catch-блока в Java? Ну, не считая всеми любимых пустых catch-блоков.
- Static Fallback Value. Вернуть какое-то статическое значение по умолчанию:
Fallback Method. Вызов альтернативного метода в случае ошибки:
Dynamic Fallback Value. Вернуть какое-то динамическое значение в зависимости от исключения:
Catch and Rethrow. Обернуть в какое-то доменное исключение и пробросить исключение дальше:
Log or React on the Side. Залогировать ошибку и пробросить исключение дальше:
Приятная новость: всё это есть в Reactor в виде эквивалентных операторов.
Менее приятная новость: в случае ошибки ваша прекрасная последовательность данных всё равно завершится (terminal event), несмотря на оператора обработки ошибок.
Подобные операторы используются скорее для создания новой, резервной (fallback) последовательности на замену завершившейся.
Можно сравнить это с похожим блоком try / catch:
Обратите внимание: for прерывается!
Ещё пример завершения последовательности в случае ошибки:
На экране получим:
Реализация try/catch
Static Fallback Value
Используя оператор onErrorReturn:
Можно добавить предикат, чтобы оператор выполнялся не для всех исключений:
Fallback Method
Используя оператор onErrorResume,
можно добавить предикат, чтобы оператор выполнялся не для всех исключений:
Dynamic Fallback Value
Всё тот же onErrorResume:
Catch and Rethrow
Можно сделать двумя способами. Первый — с оператором onErrorResume:
И более лаконично — с помощью onErrorMap:
Log or React on the Side
Добавить какой-то side effect (метрики, логирование) можно с помощью оператора doOnError
Using Resources and the Finally Block
Итак, как же получить аналог try-with-resources или блок finally? На выручку нам приходит оператор Flux.using().
Для начала нужно ознакомиться с интерфейсом Disposable. Он заставляет нас реализовать метод dispose(). Вызов этого метода должен отменять или завершать какую-то задачу или последовательность. Вызовы метода должны быть идемпотентными. Использованные ресурсы должны быть освобождены.
Повторение | Retrying
При повторе (retry) наблюдается похожее поведение, оригинальная последовательность завершается (terminate event), мы повторно подписываемся (re-subscribing) на Flux.
Разберём на примере. Код
Более сложная логика повторов доступна с использованием оператора retryWhen().
Заключение
Надеюсь, этой небольшой заметке удалось пролить свет на некоторые особенности работы Reactor.
- контекстом выполнения можно манипулировать с помощью операторов publishOn/subscribeOn и Schedulers;
- для обработки исключительных ситуаций есть множество операторов на все случаи жизни ;
- посылание terminate signal приводит к завершению оригинальной «последовательности»;
- для освобождения ресурсов используется интерфейс Dispose.
Спасибо за внимание!
Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically.
Углубляемся в Project Reactor
Привет! На прошлой неделе я рассказывал о базовых принципах работы Project Reactor. В этот раз посмотрим более сложные и интересные операторы и механизм backpressure.
Учимся говорить «нет»
Особенностью реактивных потоков является способность Subscriber’а контролировать частоту получения им ивентов. По умолчанию реактивный поток работает в неограниченном (unbounded) режиме. То есть, как только происходит публикация ивента, Subscriber его сразу же и получает.
Чтобы сбавить обороты можно либо определить собственный Subscriber, либо воспользоваться одним из встроенных операторов.
Собственный Subscriber, работающий в неограниченном режиме:
Вызываем requestUnbounded() при подписке, получаем все ивенты по мере поступления без ограничений.
OnSubscribe
OnNext: 1
OnNext: 2
OnNext: 3
В следующем Subscriber запрашиваем 1 элемент при подписке, а затем при поступлении элемента каждый раз запрашиваем ещё один:
Результат будет тем же, но общение между Publisher и Subscriber налажено совсем иначе.
На базе этого простого механизма можно построить более мощные: кэширование, буферизация, пропуск и задержка элементов, ограничение их количества или скорости поступления и т.д.
Собственно, для всего вышеперечисленного уже есть встроенные операторы. Например, пропускаем элементы, затем ограничиваем их количество:
OnNext: 4
OnNext: 5
OnNext: 6
OnNext: 7
OnNext: 8
Так как порядок имеет значение, то, поменяв операторы местами, получим другой результат:
OnNext: 4
OnNext: 5
На самом деле, при вызове нового каждого оператора создаётся новый Publisher, который добавляется к цепочке. В качестве аналогии можно привести конвейер, по которому перемещаются элементы. Операторы же по очереди проводят с ними манипуляции.
Вот так с помощью комбинации несложных действий можно получать по-настоящему впечатляющий результат. Но это ещё не всё: эффект многократно усиливается, когда наступает время объединения реактивных потоков.
Нужно больше реактивности
Счастье было бы неполным, если бы у нас не было возможности различными способами объединять Publisher’ы для получения общего эффекта. Но и тут у реактивных потоков всё в порядке: количество операторов, честно говоря, даже пугает. Поэтому разберёмся с самыми полезными и часто используемыми:
then/thenMany
При необходимости подписаться на один Publisher сразу после окончания работы другого используем оператор .thenMany (.then в случае Mono):

