

Анализ работы MS SQL Server, для тех кто видит его впервые (часть 2)
Информационный портал по безопасности
Информационный портал по безопасности » Программирование » Анализ работы MS SQL Server, для тех кто видит его впервые (часть 2)
Анализ работы MS SQL Server, для тех кто видит его впервые (часть 2)
Продолжаем анализировать что происходит на нашем MS SQL сервере.
В этой части посмотрим как получить информацию о работе пользователей: кто и что делает, сколько ресурсов на это расходуется.
Думаю, вторая часть будет интересна не только админам БД, но и разработчикам (возможно даже разработчикам больше), которым необходимо разбираться, что не так с запросами на рабочем сервере, которые до этого отлично работали в тестовом.
Анализ производительности требует глубокого понимания устройства и принципов работы сервера БД и ОС. Поэтому, чтение только этих статей не сделает из вас эксперта.
Рассматриваемые критерии и счетчики в реальных системах находятся в сложной зависимости друг от друга. Например высокая нагрузка HDD, часто связана с проблемой не самого HDD, а с нехваткой оперативной памяти. Даже если вы проведете некоторые из замеров — этого недостаточно для взвешенной оценки проблем.
Цель статей — познакомить с базовыми вещами на простых примерах. Рекомендации не стоит рассматривать как «руководство к действию», рассматривайте их как учебные задачи (упрощенно отражающие действительность) и как варианты «на подумать», призванные пояснить ход мысли.
Надеюсь, по итогу статей вы научитесь аргументировать цифрами свои заключения о работе сервера. И вместо слов «сервер тормозит» будете приводить конкретные величины конкретных показателей.
Пример как это сделать. Данный подход может пригодиться, например, для автоматического старта записи трассы в файл по расписанию. Как именно использовать эти команды, можно подсмотреть у самого профайлера. Достаточно запустить две трассировки и в одной отследить что происходит при старте второй. Обратите внимание на фильтр по колонке «ApplicationName» — проконтролируйте, что там отсутствует фильтр на сам профайлер.
Список событий фиксируемых профайлером очень обширен и не ограничивается только получением текстов запросов. Имеются события фиксирующие fullscan, рекомпиляции, autogrow, deadlock и многое другое.
sys.dm_exec_sessions — информация о сессиях. Отображает информацию по подключенным пользователям. Полезные поля (в рамках этой статьи) — идентифицирующие пользователя (login_name, login_time, host_name, program_name, . ) и поля с информацией о затраченных ресурсах (cpu_time, reads, writes, memory_usage, . )
sys.dm_exec_requests — информация о запросах выполняющихся в данный момент. Полей тут тоже довольно много, рассмотрим только некоторые:
- session_id — код сессии для связи с предыдущим представлением
- start_time — время старта запроса
- command — это поле, вопреки названию, содержит не запрос, а тип выполняемой команды. Для пользовательских запросов — обычно это что-то вроде select/update/delete/и т.п. (также, важные примечания ниже)
- sql_handle, statement_start_offset, statement_end_offset — информация для получения текста запроса: хэндл, а также начальная и конечная позиция в тексте запроса — обозначающая часть выполняемую в данный момент (для случая когда ваш запрос содержит несколько команд).
- plan_handle — хэндл сгенерированного плана.
- blocking_session_id — при возникновении блокировок препятствующих выполнению запроса — указывает на номер сессии которая стала причиной блокировки
- wait_type, wait_time, wait_resource — поля с информацией о причине и длительности ожидания. Для некоторых видов ожидания, например, блокировка данных — дополнительно указывается код заблокированного ресурса.
- percent_complete — по названию понятно, что это процент выполнения. К сожалению, доступен только для команд у которых четко прогнозируемый прогресс выполнения (например, backup или restore).
- cpu_time, reads, writes, logical_reads, granted_query_memory — затраты ресурсов.
Приведенный перечень — лишь малая часть. Полный список всех системных представлений и функций описан в документации. Также, имеется схема связей основных объектов в виде красивой картинки — можно распечатать на А1 и повесить на стену.
Текст запроса, его план и статистика исполнения — данные хранящиеся в процедурном кэше. Во время выполнения они доступны. После выполнения доступность не гарантируется и зависит от давления на кэш. Да, кэш можно очищать вручную. Иногда это советуют делать когда «поплыли» планы выполнения, но тут очень много нюансов… В общем, «Имеются противопоказания, рекомендовано проконсультироваться со специалистом».
Поле «command» — для пользовательских запросов оно практически бессмысленно — ведь мы можем получить полный текст… Но не всё так просто. Это поле очень важно для получения информации о системных процессах. Как правило, они выполняют какие-то внутренние задачи и не имеют текста sql. Для таких процессов, информация о команде единственный намек на тип активности. В комментариях к предыдущей статье был вопрос про то, чем занят сервер, когда он, вроде бы, ничем не должен быть занят — возможно ответ будет в значении этого поля. На моей практике, поле «command» для активных системных процессов всегда выдавало что-то вполне понятное: autoshrink/autogrow/checkpoint/logwriter/и т.п.
Как же это использовать
Перейдем к практической части. Я приведу несколько примеров использования, но не стоит ограничивать вашу фантазию. Возможности сервера этим не исчерпываются — можете придумывать что-то своё.
Пример 1: Какой процесс расходует cpu/reads/writes/memory
Для начала, посмотрим какие сессии больше всего потребляют, например, CPU. Информация в sys.dm_exec_sessions. Но данные по CPU (а также reads, writes) — накопительные. Т.е цифра в поле содержит «итого» за все время подключения. Понятно, что больше всего будет у того кто подключился месяц назад, да так и не отключался ни разу. Это вовсе не означает, что он прямо сейчас грузит систему.
Немного кода решает проблему, алгоритм примерно такой:
В коде я использую две таблицы: #tmp — для первой выборки, #tmp1 — для второй. При первом запуске, скрипт создает и заполняет #tmp и #tmp1 с интервалом в одну секунду, и делает остальную часть. При последующих запусках, скрипт использует результаты предыдущего выполнения в качестве базы для сравнения. Соответственно, длительность п.2 при последующих запусках будет равна длительности вашего ожидания между запусками скрипта. Пробуйте выполнять, можно сразу на рабочем сервере — скрипт создает только «временные таблицы» (доступны только внутри текущей сессии и самоуничтожаются при отключении) и не несёт в себе опасности.
Те, кто не любят выполнять запрос в студии — могут его завернуть в приложение написанное на своём любимом языке программирования. Я покажу как это сделать в MS Excel без единой строки кода.
В меню «Данные» подключаемся к серверу. Если будет требовать выбрать таблицу — выбираем произвольную — потом поменяем это. Как всегда, жмем «Next» и «Finish» пока не увидим диалог «Импорт данных» — в нем нужно нажать «Свойства. ». В свойствах необходимо сменить «тип команды» на значение «SQL» и в поле «текст команды» вставить немного измененный наш запрос.
Запрос придется немного поменять:

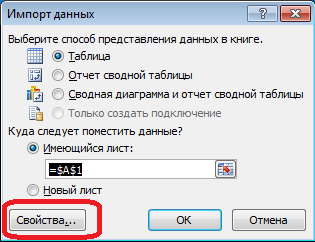


Когда данные будут в Excel-е, можете их сортировать как вам нужно. Для актуализации информации — жмите «Обновить». В настройках книги, для удобства, можете поставить «автообновление» через заданный период времени и «обновление при открытии». Файл можете сохранить и передать коллегам. Таким образом, мы из навоза и веточек подручных средств собрали ЫнтерпрайзМониторингТул удобный и простой инструмент.
Пример 2: На что сессия расходует ресурсы
Итак, в предыдущем примере мы определили проблемные сессии. Теперь определим, что именно они делают. Используем sys.dm_exec_requests, а также функции получения текста и плана запроса.
Подставляйте в запрос номер сессии и выполняйте. После выполнения, на закладке «Results» будут планы (два: первый для всего запроса, второй для текущего шага — если шагов в запросе несколько), на закладке «Messages» — текст запроса. Для просмотра плана — необходимо кликнуть в строке на текст оформленный в виде url. План откроется в отдельной закладке. Иногда бывает что план открывается не в графическом виде, а в виде xml-текста. Это, скорее всего, связано с тем что версия студии ниже чем сервера. Попробуйте пересохранить полученный xml в файл с расширением sqlplan, предварительно удалив из первой строки упоминания «Version» и «Build», а затем отдельно открыть его. Если и это не помогает — напоминаю, что 2016 студия официально доступна бесплатно на сайте MS.
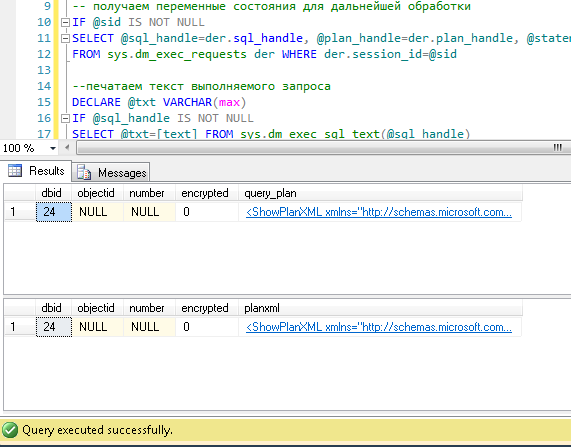

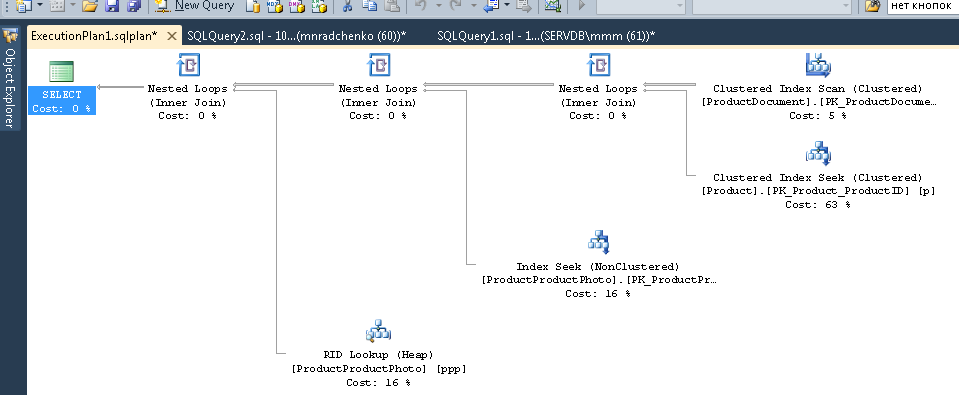
Очевидно, полученный план будет «оценочным», т.к. запрос еще выполняется. Но некоторую статистику по выполнению получить всё равно можно. Используем представление sys.dm_exec_query_stats с фильтром по нашим хэндлам.
Допишем в конец предыдущего запроса
После выполнения, в результатах получим информацию о шагах выполняемого запроса: сколько раз они выполнялись и какие ресурсы потрачены. Информация в статистику попадает после выполнения — при первом выполнении там, к сожалению, пусто. Статистика не привязана к пользователю, а ведется в рамках всего сервера — если разные пользователи выполняют один и тот же запрос — статистика будет суммарная по всем.
Пример 3: А можно всех посмотреть
Давайте объединим рассмотренные системные представления и функции в одном запросе. Это может быть удобно для оценки ситуации в целом.
Запрос выводит список активных сессий и тексты их запросов. Для системных процессов, напоминаю, обычно запрос отсутствует, но заполнено поле «command». Видна информация о блокировках и ожиданиях. Можете попробовать скрестить этот запрос с примером 1, чтобы еще и отсортировать по нагрузке. Но будьте аккуратны — тексты запросов могут оказаться очень большими. Выбирать их массово может оказаться ресурсоемко. Да и трафик будет большим. В примере я ограничил получаемый запрос первыми 500 символами, а получение плана не стал делать.
Примеры запросов выложил на гитхаб.
Заключение
Было бы ещё неплохо, получить Live Query Statistics для произвольной сессии. По заявлению производителя, на текущий момент, постоянный сбор статистики требует значительных ресурсов и поэтому, по умолчанию, отключен. Включить не проблема, но дополнительные манипуляции усложняют процесс и уменьшают практическую пользу. Возможно, попробуем это сделать в отдельной статье.
В этой части мы рассмотрели анализ действий пользователей. Попробовали несколько способов: используя возможности самой студии, используя профайлер, а также прямые обращения к системным представлениям. Все эти способы позволяют оценить затраты на выполнение запроса и получить план исполнения. Ограничиваться одним из них не нужно — каждый способ удобен в своей ситуации. Пробуйте комбинировать.
Впереди у нас еще анализ нагрузки на память и сеть, а также прочие нюансы. Дойдем и до них. Материала еще на несколько статей.
Основы администрирования SQL Server (шпаргалка начинающего администратора)

SQL Server для чайников
Анализ рынка вакансий показал, что Вакансий для начинающего администратора баз данных (далее Junior DBA) мало и работодатель требует как минимум некоторый опыт работы в информационных технологиях, чаще,конечно, требуется реальный опыт работы с БД. Такая ситуация приводит к тому, что устроиться на данную вакансию сложно.
Почему компании не хотят нанимать Junior DBA
Базы данных являются центральным ядром многих компаний, они хранят в себе платежи, личные данные и корпоративную информацию, без которой существование организации станет невозможным. Компании стремятся уменьшить риски потери или утечки информации и не хотят брать на роль DBA сотрудников без опыта работы. По этой причине компании более склонны обучить своих сотрудников, чем брать начинающего DBA (Junior DBA).
Обычно, большие компании берут Junior DBA на определённую работу, которая, как правило, низкоквалифицирована и направлена на помощь опытным администраторам баз данных (Senior DBA). В такой компании вы можете столкнуться с тем, что вам будет сложно пробиться дальше, так как никто не хочет терять работу, но для стажа работы и некоторого опыта общения этот вариант может быть интересен.
Сертификация не так полезна для Junior DBA
Не стремитесь к сертификатам в начале вашей карьеры. Сертификат — это как украшение новогодней Ёлки, но если ёлка не может устойчиво стоять, то украшения ей не помогут. Сертификат будет служить дополнительным плюсом при поиске работы, но не тратьте на него времени, если у вас нет базовых знаний администрирования.
Когда полезна сертификация
- Для прохождения первых этапов отбора
- Для принятия решения в вашу пользу если кандидаты одинаковы
- Для поддержания вашего интереса к технологии
- Необходим для организаций, где есть тендеры
Как выбрать место работы для Junior DBA
В начале вашей карьеры следует обращать больше внимание не на зарплату, а на коллектив. Вам необходимо найти такое место работы, где вы сможете перенять опыт у ваших коллег. Вам очень повезёт, если вы сможете найти достойного наставника, тогда ваш карьерный рост будет стремительным. Если вы устраиваетесь на работу где нет других ДБА, то вам придётся самостоятельно проходить все сложности обучения и очень вероятно что это обучение будет сопровождаться авариями и другими сложностями, в таком случае будет полезно иметь знакомых, опытных администраторов БД, которым можно задать вопросы по телефону.
Чтобы стать Senior DBA вам необходимо постоянно развиваться. Вот несколько вариантов как вы можете это делать:
- Посещать курсы
- Посещать мероприятия
- Читать сайты и форумы
- Задавать вопросы на форумах и сайтах
- Смотреть обучающее видео
- Старайтесь делать на работе больше, чем вас просят (изучать каждую тему глубже)
Пора переходить к нашей теме.
Что нужно знать начинающим администраторам БД:
- Модели восстановления (обязательная тема для любого кто планирует заниматься работой администратора баз данных. Эту тему надо понимать в полном объёме (FULL,LOG) (https://msdn.microsoft.com/ru-ru/library/ms189275.aspx)
— FULL https://technet.microsoft.com/ru-ru/library/ms190217(v=sql.105).aspx
— LOG https://technet.microsoft.com/ru-ru/library/ms191164.aspx - После изучения моделей восстановления, обязательно проведите самостоятельное тестирование с полным и частичным восстановлением (Restore)
- Безопасность уровня БД и сервера
- Изучение лога ошибок
- Конфигурация и установка
- Простые запросы
- Базовые понятия производительности сервера (плохо ему или хорошо)
- Индексы и статистика
- CHECKDB
- Варианты отказоустойчивости (Log Shipping, Mirroring, Failover Cluser, AlwaysOn). Отказоустойчивость ни в коем случае не отменяет необходимость делать резервные копии
Советы начинающим администраторам БД
- Делайте Backup перед любыми изменениями в БД
- Если вы выполняете добавление, обновление или удаление данных, то можно явно открыть транзакцию BEGIN TRANSACTION > выполнить ваш код > прочитать таблицу с параметром NOLOCK (позволяет читать незафиксированные данные) SELECT * FROM MyTable WITH (NOLOCK)> если всё прошло успешно, можно зафиксировать транзакцию — COMMIT TRANSACTION
- Пишите комментарии, они не раз помогут вам при разборе вашего кода, когда вы вернётесь к нему спустя некоторое время
- Скачайте для практики SQL Server Developer Edition (2014/16 бесплатны). Данная редакция имеет только одно ограничение — запрет на использование в продуктивных системах, что позволит вам практиковаться на всех компонентах SQL Server.
- Старайтесь отслеживать любые изменения на сервере БД, так как отвечать придётся именно вам, даже если изменения сделали другие
- Не вносите критические изменения, которые могут повлиять на производительность или доступность системы, без согласования с пользователями и вашим руководством
В конце хотелось бы добавить, что во время интенсивного обучения крайне важно отдыхать. Хороший сон позволит вам лучше усваивать материал, а периодические перерывы помогут по другому смотреть на ситуацию, но ни в коем случае не путайте полезные перерывы с ленью.
Вам так же будет полезно изучить вопросы для собеседование на позицию Администратор MS SQL SERVER
Анализ работы MS SQL Server, для тех кто видит его впервые
Недавно столкнулся с проблемой — занедужил SVN на ubuntu server. Сам я программирую под windows и с linux “на Вы”… Погуглил по ошибке — безрезультатно. Ошибка оказалась самая типовая (сервер неожиданно закрыл соединение) и ни о чем конкретном не говорящая. Следовательно, надо погружаться глубже и анализировать логи/настройки/права/и т.п., а с этим, как раз, я “на Вы”.
В результате, конечно, разобрался и нашел всё что нужно, но время потрачено много. В очередной раз думая, как глобально (да-да, во всём мире или хотя бы на ⅙ части суши) уменьшить бесполезно потраченные часы — решил написать статью, которая поможет людям быстро сориентироваться в незнакомом программном обеспечении.
Писать я буду не про линукс — проблему хоть и решил, но профессионалом вряд ли стал. Напишу про более знакомый мне MS SQL. Благо, уже приходилось много раз отвечать на вопросы и список типовых уже готов.
Если вы админ в Сбере (или в Яндексе или ), вы можете сохранить статью в избранное. Да, пригодится! Когда к вам, в очередной раз, с одними и теми же вопросами придут новички — Вы дадите им ссылку на нее. Это сэкономит Ваше время.
Если без шуток, эта СУБД часто используется в небольших компаниях. Часто совместно с 1С либо другим ПО. Отдельного БД-админа таким компаниям держать затратно — надо будет выкручиваться обычному ИТ-шнику. Для таких и пишу.
Какие проблемы рассмотрим
Если сервер вам сообщает “закончилось место на диске Е” — глубокий анализ не нужен. Не будем рассматривать ошибки, решение которых очевидно из текста сообщения. Также не будем рассматривать ошибки по которым гугл сразу выдает ссылку на msdn с решением.
Рассмотрим проблемы по которым не очевидно что гуглить. Такие как, например, внезапное падение производительности или, например, отсутствие соединения. Рассмотрим основные инструменты для настройки. Рассмотрим средства анализа. Поищем где лежат логи и другая полезная информация. И в целом, попробую в одной статье собрать нужную информацию для быстрого старта.
Начнем с лидера списка частых вопросов, настолько он опережает всех, что рассмотрим его отдельно. Вдобавок, об этом пишут во всех статьях про работу MS SQL — и я не буду нарушать традицию.
Если у вас вдруг, ни с того ни с сего, стало работать медленно, а вы ничего не меняли (как поставили, так всё и работало, никто ничего не трогал) — в первую очередь, обновите статистику и перестройте индексы. Только удостоверившись, что это выполнено — имеет смысл копать глубже. Еще раз подчеркну — делать это нужно обязательно, вопрос только как часто.
В интернете полно рецептов как это делать, приводятся примеры скриптов. Предположу, что все те методы для “профи” и новичкам непонятны. Что ж, опишу способ наипростейший: для его внедрения вам потребуется только владение мышью.
- SSMS — приложение “ Microsoft SQL Server Management Studio”, находится в “Пуске”. Устанавливается отдельной галочкой (Client management tools) с дистрибутива сервера. Начиная с 2016 версии, доступно бесплатно на сайте MS в виде отдельного приложения. Старшие версии студии нормально работают с младшими версиями сервера. Наоборот — тоже иногда работают (основные функции).
docs. microsoft .com/en-us/sql/ssms/download-sql-server-management-studio-ssms “SSMS is free! It does not require a license to install and use.” - Profiler — приложение “SQL Server Profiler”, находится в “Пуске”, устанавливается вместе с SSMS.
- Performance Monitor (Системный монитор) — оснастка панели управления. Позволяет мониторить счетчики производительности, журналировать и просматривать историю замеров.
Обновление статистики с помощью “плана обслуживания”:
- запускаем SSMS;
- подключаемся к нужному серверу;
- разворачиваем в Object Inspector дерево: Management Maintenance Plans (Планы обслуживания)
- правой кнопкой на узле, выбираем “Maintenance Plan Wizard”
- в визарде мышкой отмечаем нужные нам задачи:
- rebuild index (перестроить индекс)
- update statistics (обновить статистику)
- отметить можно обе задачи сразу, либо сделать два плана обслуживания по одной задаче в каждом (смотрим “важные замечания” ниже);
- далее, отмечаем галочками нужную нам БД (или несколько). Делаем это для каждой задачи (если выбрали две задачи — будет два диалога с выбором БД).
- Next, Next, Finish
После этих действий у вас создастся (а не выполнится) “план обслуживания”. Запуск можно выполнить вручную — правой кнопкой на нем, выбрать “Execute”. Либо настроить запуск через “SQL Agent”.
- Обновление статистики — неблокирующая операция. Можно выполнять в рабочем режиме. Дополнительную нагрузку конечно создаст, но ведь у вас и так всё тормозит, будет чуть больше — незаметно.
- Перестроение индекса — блокирующая операция. Запускать только в нерабочее время. Есть исключение — Enterprise редакция сервера допускает выполнение “онлайнового ребилда”. Эта опция включается галочкой в настройках задачи. Обратите внимание, галочка есть во всех редакциях, но работает только в Enterprise.
- Конечно, эти задачи необходимо выполнять регулярно. Предлагаю простой способ определения, как часто это делать:
- при первых проблемах выполняете план обслуживания;
- если помогло — ждете пока не начнутся проблемы снова (как правило, до очередного закрытия месяца/расчета зп/ и т.п. массовых операций);
- получившийся срок нормальной работы и будет вам ориентиром;
- например, настройте выполнение плана обслуживания в два раза чаще.
Сервер работает медленно — что делать?
Используемые сервером ресурсы
Как и любой другой программе, серверу нужны: время процессора, данные на диске, объемы оперативной памяти и пропускная способность сети.
Оценить нехватку того либо иного ресурса в первом приближении можно с помощью Task Manager (Диспетчер задач), как бы по кэпски это не звучало.
Посмотреть загрузку в диспетчере сможет даже школьник. Здесь нам надо просто убедиться, что если процессор загружен, то именно процессом sqlserver.exe.
Если это ваш случай, то надо переходить к анализу активности пользователей, чтобы понять, что именно стало причиной загрузки (листаем ниже).
Многие смотрят только загрузку процессора, но не надо забывать что СУБД — это хранилище данных. Объемы данных растут, производительность процессоров растет, а скорость HDD практически не меняется. С SSD ситуация получше, но терабайты на них хранить затратно.
Получается так, что я чаще сталкиваюсь с ситуациями, когда узким местом становится именно дисковая система, а не ЦПУ.
Для дисков нам важны следующие показатели:
- средняя длина очереди (операций ввода-вывода ожидающих выполнения, штук);
- скорость чтения-записи (в Мб/с).
Серверная версия диспетчера задач, как правило (зависит от версии системы), показывает и то и другое. Если нет — запускаем оснастку панели управления “Performance Monitor” (Системный монитор). Нас интересуют счетчики:
- Физический (логический) диск / Среднее время чтения (записи)
- Физический (логический) диск / Средняя длина очереди диска
- Физический (логический) диск / Скорость обмена с диском
Развернуто — можно почитать мануалы производителя, например тут social.technet. microsoft .com/wiki/contents/articles/3214.monitoring-disk-usage.aspx. В кратце:
- Очередь желательно чтобы не превышала 1. Допустимы кратковременные всплески, если они быстро спадают. Всплески могут быть разными в зависимости от вашей системы. Для простого рэйда-зеркала из двух HDD — очередь больше 10-20 проблема. Для крутой библиотеки с супер кешированием я видел всплески до 600-800 которые мгновенно рассасывались, не приводя к задержкам.
- Нормальная скорость обмена тоже варьирует от типа дисковой системы. Обычный (настольный) HDD “качает” по 50-100 Мб/с. Хорошая дисковая библиотека по 500 Мб/с и более. Для мелких случайных операций скорость меньше. Примерно так и ориентируйтесь.
- Эти параметры надо смотреть в комплексе. Если ваша библиотека качает 50Мб/с и при этом выстраивается очередь в 50 операций — явно что-то не так с железом. Если очередь выстраивается при прокачке близкой к максимальной — то скорее всего диски не виноваты — они просто больше не могут — надо искать способ уменьшить нагрузку.
- Нагрузку надо смотреть раздельно по дискам (если их несколько) и сопоставлять с размещением файлов сервера. Диспетчер задач может показать наиболее активно используемые файлы. Это удобно использовать, чтобы убедиться, что нагрузка идет именно от СУБД.
Чем могут быть вызваны проблемы с дисковой системой:
- проблемы с железом
- погорел кэш, резко упала производительность;
- дисковая система используется чем-то еще;
- Недостаток оперативной памяти. Свопинг. Ухудшилось кэширование, производительность упала (смотрим раздел про ОП ниже).
- Увеличилась пользовательская нагрузка. Необходимо оценить работу пользователей (проблемный запрос / новый функционал / увеличение количества пользователей / увеличение объема данных / и т.п.).
- Фрагментация данных БД (смотрим ребилд индексов выше), фрагментация файлов системы.
- Дисковая система достигла своих максимальных возможностей.
Если у вас последний вариант — не спешите выкидывать оборудование. Иногда из системы можно выжать чуть больше если подойти к проблеме с умом. Проверьте размещение файлов системы на соответствие рекомендуемым требованиям:
- не смешивайте файлы ОС с файлами данных БД. Размещайте их на физически разных носителях чтобы система не конкурировала с СУБД за ввод-вывод.
- БД состоит из файлов двух видов: данные (*.mdf, *.ndf) и логи (*.ldf). Файлы данных, как правило, больше используются на чтение. Логи — больше на запись (причем запись — последовательная). Из понимания этого факта, следует рекомендация размещать логи и данные на физически разных носителях, чтобы запись в лог не прерывала чтение данных (как правило, операция записи имеет приоритет выше чем у чтения).
- MS SQL для обработки запросов может использовать “временные таблицы”. Они хранятся в системной базе tempdb. Если у вас высокая нагрузка на файлы этой БД — то можно попробовать вынести ее на физически отдельные носители.
Резюмируя по размещению файлов, используйте принцип “разделяй и властвуй”. Оцените к каким файлам идут обращения и попробуйте их распределить на разные носители. Также, используйте особенности RAID систем. Например, RAID-5 читает быстрее чем пишет — что хорошо подходит для файлов данных.
- анализируем использование ОП и сети.
- смотрим детально работу пользователей используя SSMS, profiler и прямые запросы к системным представлениям.
- план и статистика запросов (рассмотрим несколько способов получения). live query statistics.
- waits (ожидания). текущая информация и статистика.
- проблемы с подключением к серверу. процессы/порты/протоколы
Реклама помогает поддерживать и развивать наши сервисы

